Before addressing the definition, appearance, engineering and management of Ontologies in the Information System Management domain, we should first remember the linkage with the Knowledge Management domain and the importance of the “Data-Information-Knowledge-Wisdom hierarchy, DIKW”.
“…
Where is the wisdom we have lost in knowledge?
Where is the knowledge we have lost in information?
…”
T.S. Eliot, “Choruses”, “The Rock”, 1934.
Back to eighties, DIKW has been defined as a pyramid showing the elaboration of Information from raw Data, the elaboration of Knowledge from the combination of Informations, and the use of Knowledge for supporting thinking and making action decisions, which brings Wisdom to people.
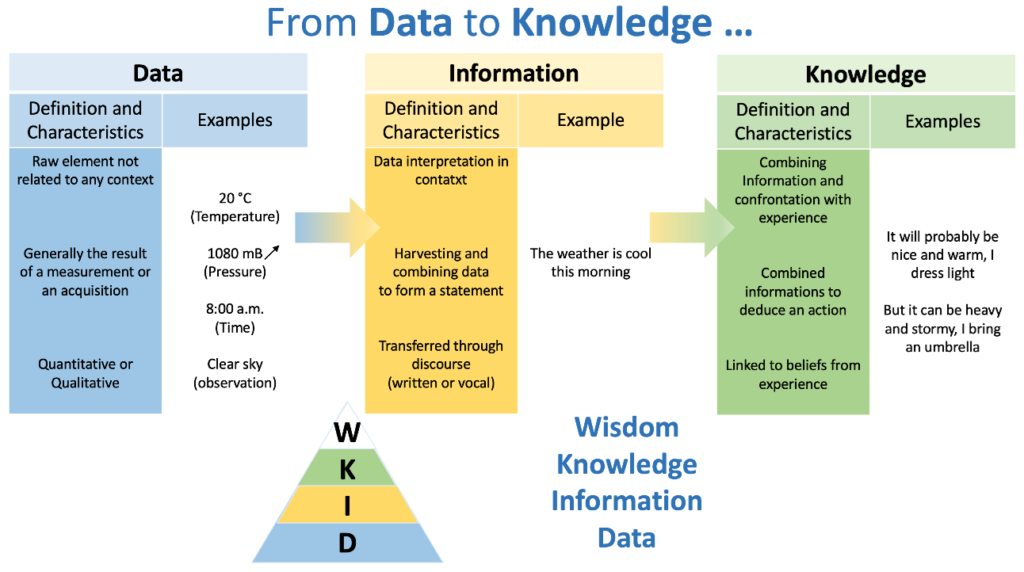
In the nineties, knowledge was qualified as either tacit (drawn from the ability of people to perform repeatedly the same actions with the same outcomes) or explicit (formalized to a level which allows its unambiguous understanding).
Tacit knowledge is passed within a group of people by means of for example human observation and reproduction attempts, which requires at least the communication between two person (the one who knows and practices, and the one who observes and repeats : “Master and Disciple”) ; whereas explicit knowledge, which is highly structured, and well defined and described, doesn’t require the coordination of people to achieve the knowledge transfer (for example, books harvesting this explicit knowledge can be used by anybody to learn, assimilate and apply this knowledge in practice).
So, tacit knowledge can be transferred by Socialization, can be formalized into explicit knowledge by Externalization. Since explicit knowledge is formalized, it can be extended by Combination with another explicit knowledge. And, finally, when individuals learn, assimilate and apply this explicit knowledge in practice, they proceed by Internalization.
In 1995, Nonaka and Takeuchi proposed this SECI Model, and explained it using the following diagram:
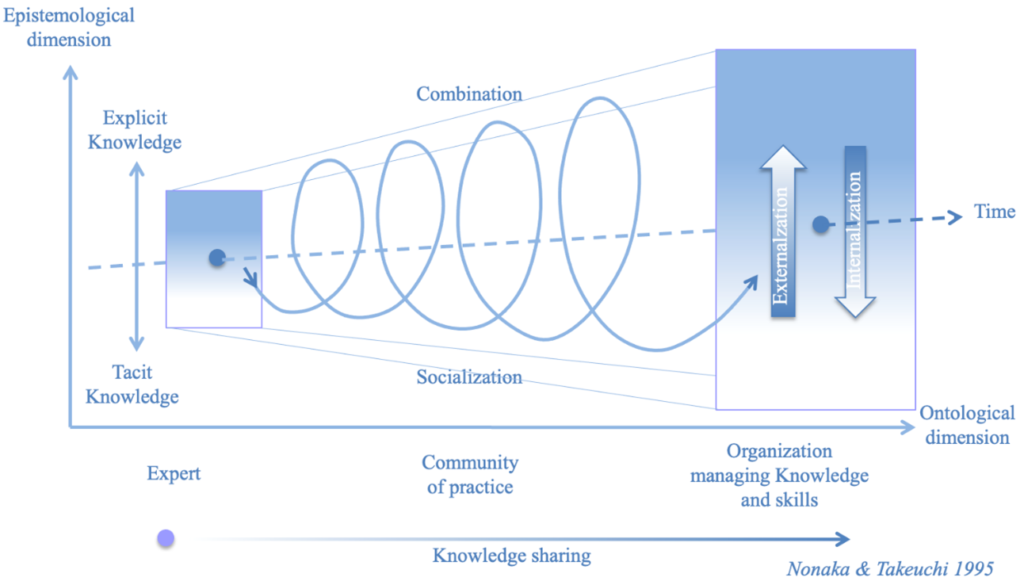
We can see through this picture that knowledge flows from an individual, expert implementation to a shared understanding and practice of this knowledge managed within the enterprise and broader.
We can also see that Ontologies are created along the repeated SECI process and leverage Combination.
What Is An Ontology?
In the Information System Management domain, the definition of “Ontology” varied along the past 30 years.
There is no unanimously agreed-upon definition what an ontology is.
But we can provide a simple sentence contributing to this definition:
An ontology is a representation of concepts and relationships among them within a domain of interest
But then, what is the difference between an ontology and a conceptual representation of data expressed using an Entity-Relationship (ER) or UML modeling?
On one hand, we can “intuitively” all agree that a conceptual data model, especially a UML model, is an application specific, implementation independent representation of the data which will be (are) managed by this application.
On the other hand, an ontology, is an application independent representation of a domain of interest (embracing a larger context than the one of a set of applications).
In addition, ontologies are formalized using a logic language allowing the explicit specification of the rules which constrain the expressed knowledge: these included rules provide the user with reasoning capabilities, leading to inferring implicit knowledge.
On this basis, we could state that these ER or UML application specific models translated into an “ontology language”, such as OWL, becomes an “operational ontology”.
Note that although some people might argue that we could use ER modeling for conceptually representing data in a broader context than the one of this application, hence attempting to conceptually “integrate” data across applications, this representation is more often a structural representation of data, not considering the rules which control them.
Finally, an ontology is expressed in a text file, using a description logic language, containing structured knowledge (concepts, relationships and rules) about a specific domain of interest.
What Are Ontologies Used For?
We saw in the previous chapter that an ontology provides “an explicit representation of concepts, relationships and rules, formally describing the knowledge about a given domain of interest”.
Within this domain of interest, multiple operational applications and databases have been implemented, and it is likely that some “common” concepts might have been translated into different structures according to the needs of these applications.
Since ontologies are application independent, they provide the support for integrating the data across the different applications.
For example, the data which transit through the Application Programming Interfaces can be defined and structured based on the knowledge structured in the ontology which “integrates” the application dependent data.
This integration within the scope of the enterprise can be extended to the data at the boundary of the enterprise, and, likewise, the data integration between companies can be ensured based on the existence of ontologies providing the formal representation of the knowledge within a given industrial sector or defining explicitly the knowledge structuring specific communications between companies.
With an Enterprise Data Management perspective, ontologies provide the necessary semantic level for governing the definition and use of data within the enterprise and across companies, avoiding application dependence. By managing the translation across the levels of the Data Architecture domain.
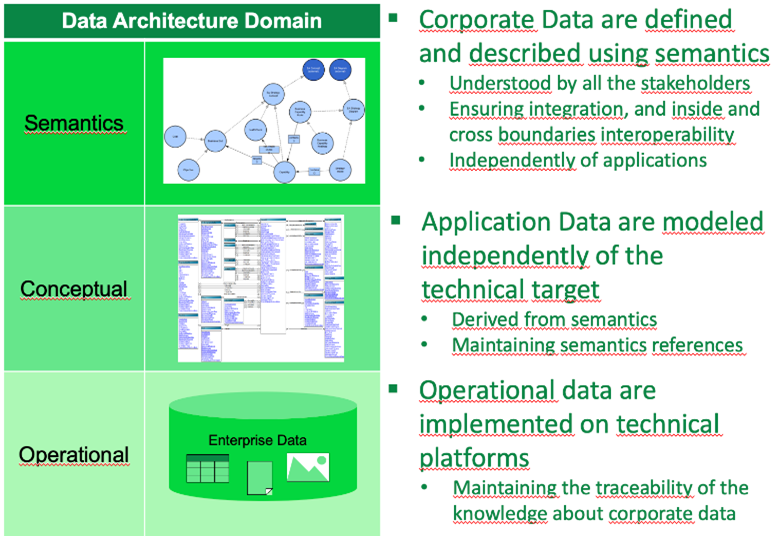
How To Create Them?
We saw in chapter 2 that ontologies are expressed using a formal logic language. The most used language is OWL (Web Ontology Language) defined and maintained by the W3C consortium.
As defined by the W3C, OWL is
“a Semantic Web language designed to represent rich and complex knowledge about things and relations between them. OWL is a computational logic-based language such that knowledge expressed in OWL can be exploited by computer programs, e.g., to verify the consistency of that knowledge or to make implicit knowledge explicit”.
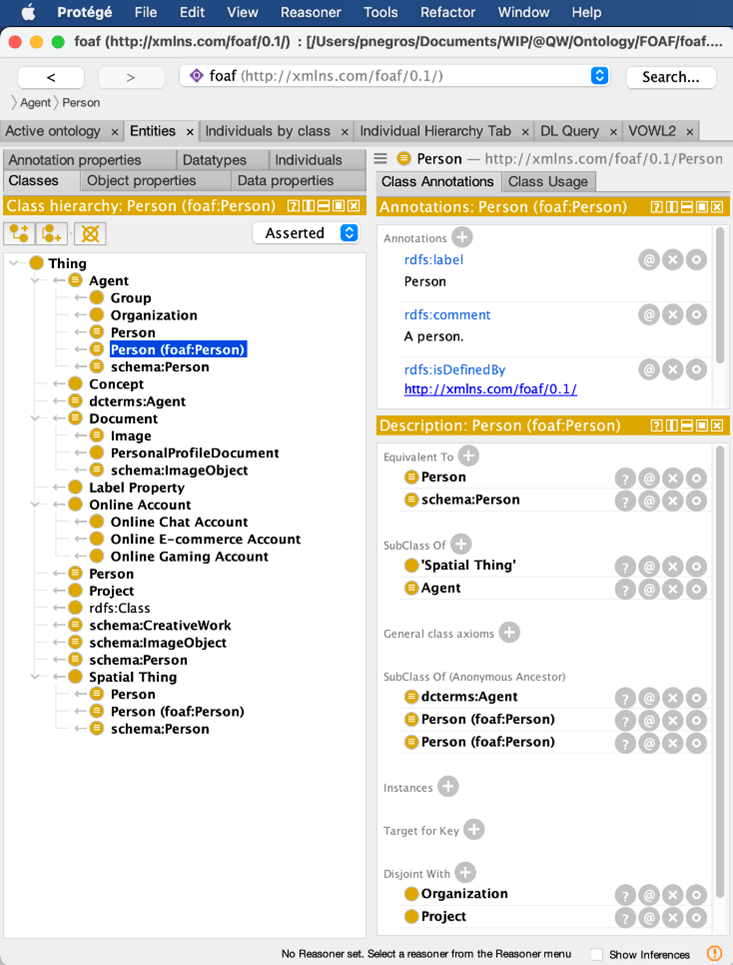
As an example, here is the OWL definition of “Person” in the “Friend of a Friend” ontology:

To help ontology users/developers using and managing their ontology, an ontology editing environment has been developed by Stanford University: Protégé (https://protege.stanford.edu).
The following pictures shows the edited Class hierarchy of the “Friend of a friend” ontology:
And the defined ObjectProperties:
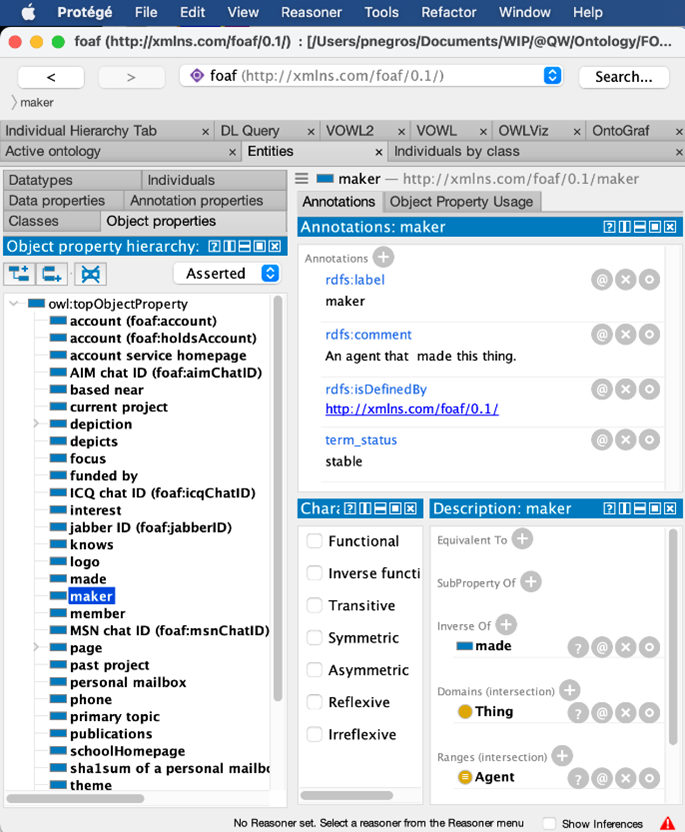
In this environment, users define their ontology (class hierarchy, object and data properties relating the classes, constraints, …) links it to standard and upper ontologies which they refer to, …
This environment, which can be augmented by means of plugins provides the users with inference capabilities, allowing them to extend the ontology by making explicit statements from implicit knowledge.
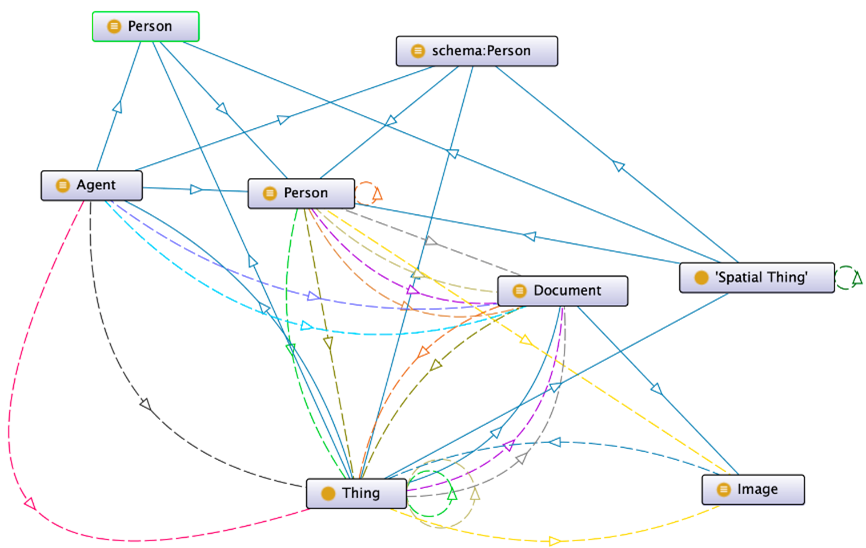
Among the plugins, there are visualization features which translate the “textual” ontology into graphs such as “OntoGraf” which shows selected Classes as boxes and ObjetProperties as arcs:
Or “VOWL” (http://vowl.visualdataweb.org/v2/) which fully translates the ontology into a graph showing classes, object and data properties and constraints:
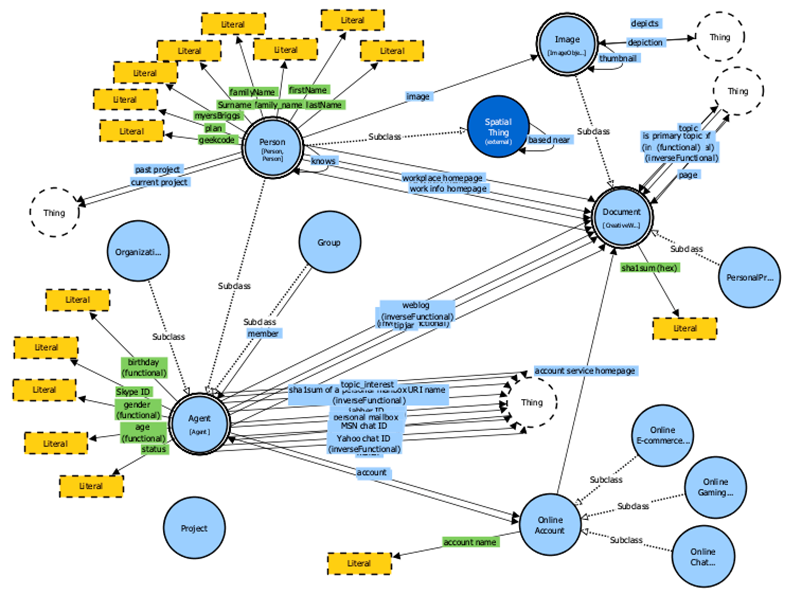
These obtained diagrams are just visualization reports and cannot be edited in Protégé.
QualiWare made the decision to provide Data Architects with graphically editing ontologies based on VOWL, with the future possibility of round-tripping between QualiWare and Protégé:
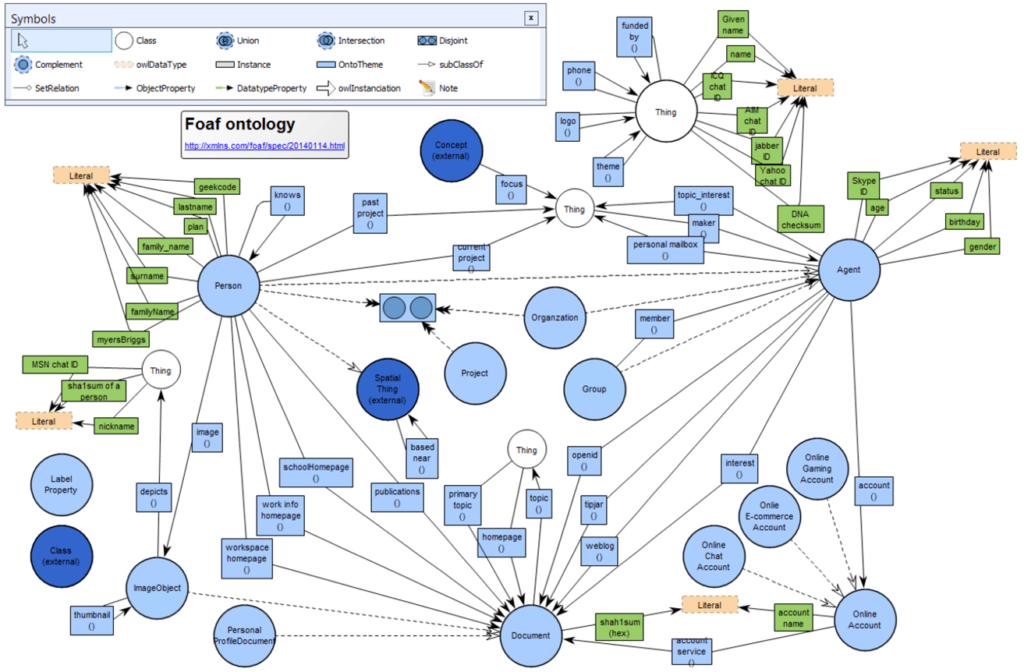
Using the “GOWL” metamodel Data Architects can document and model the enterprise semantics and relate them with conceptual information models, hence linking the enterprise knowledge about Data from semantics to operational implementations of data.
Following this approach, the enterprise can harmonize its data at the level of cross enterprise shared semantics and easier govern its Data Architecture among the Business Units.
These semantics also become the trusted source for defining the data exposed/captured through APIs, bringing inhouse and external interoperability.
How To Manage Ontologies?
Standard ontologies have been defined and are managed and controlled by the W3C consortium.
Among these we can list:
- FOAF (http://xmlns.com/foaf/0.1/)
- « Friend of a friend », describes Persons and the relations they have. It is a central ontology for the semantic web.
- TIME (https://www.w3.org/TR/owl-time/)
- Describes temporal objects and the temporal properties of resources. It is highly used within the semantic web.
- SKOS (https://www.w3.org/2004/02/skos/)
- « Simple Knowledge Organization System » describes the means for sharing and linking knowledge systems within the semantic web.
- PROV-O (https://www.w3.org/TR/prov-o/)
- Describes the classes, properties and constraints for representing the provenance of resources within the semantic web.
- HYDRA (https://www.hydra-cg.com/spec/latest/core/)
- Describes the vocabulary to create hypermedia-driven Web APIs, specifying a number of concepts commonly used in Web APIs, and enabling the creation of generic API clients.
- …
Other dedicated consortiums and standard bodies propose standard ontologies for describing specific domain of interests.
As an example, the SAREF (« Smart Applications REFerence » : https://saref.etsi.org) ontology provides the building blocks for describing the assets of the smart applications domain (e.g. in the IoT context).
SAREF is composed of a Core ontology with specific focus-driven ontologies (e.g. Command, or Device) as well as domain specific extensions such as SAREF4ENER (Energy), SAREF4BLDG (Building), SAREF4CITY (City), …
SAREF is under control of ETSI (« European Telecommunication Standard Institute »).
SAREF Core:
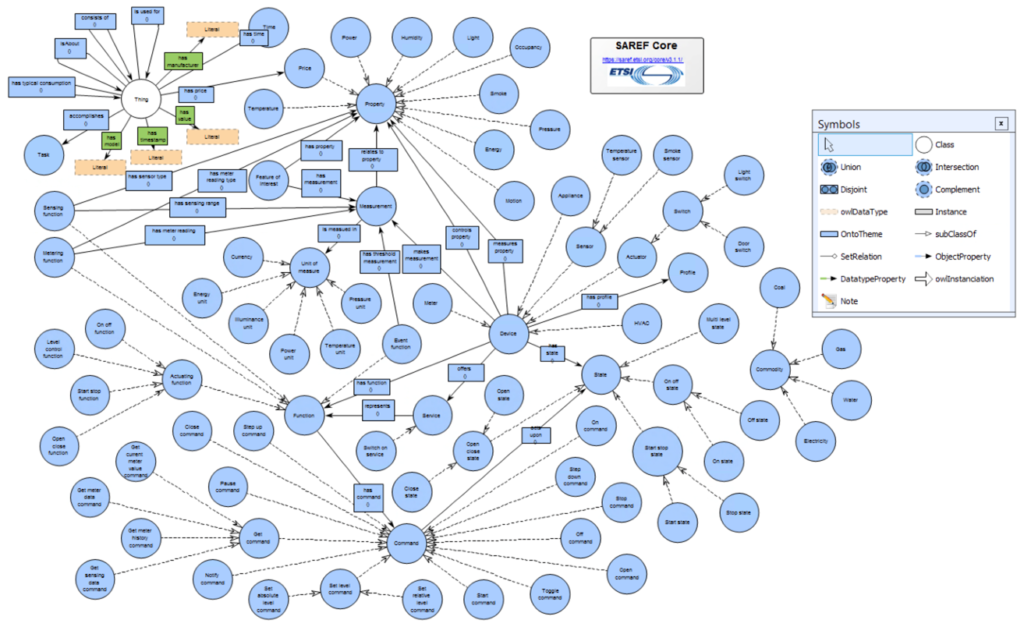
In addition, Ontologies have been classified based on their type of support to ontology engineering. The top-level ontologies are called Upper Ontologies. We find in that group useful ontologies for Natural Language processing (DOLCE) or for formally addressing static and dynamic high-level concepts (BFO), these upper and standards ontologies avoid users to « reinvent the wheel ».
How To Engineer Ontologies?
There is not just one methodology for engineering ontologies, but the many possibilities share useful steps which can be summarized in the following picture (« The state of practice in ontology engineering in 2009 », Elena Simperl & al., the International Journal of Computer Science and Applications):
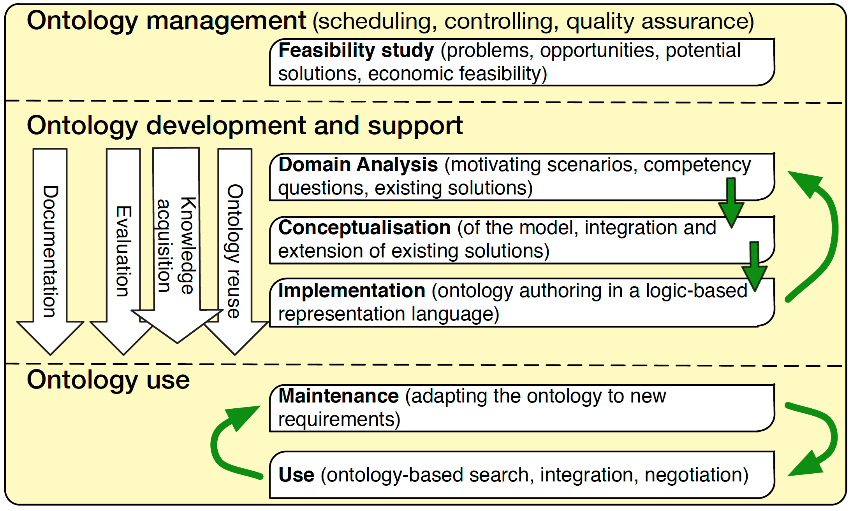
This picture covers the full set of activities dedicated to Ontology engineering, but we will focus on the sub-set addressing Ontology Development.
The most used methodologies in this scope are METHONTOLOGY (https://www.aaai.org/Papers/Symposia/Spring/1997/SS-97-06/SS97-06-005.pdf) and NeON (https://oa.upm.es/5475/1/INVE_MEM_2009_64399.pdf)), and the one developed by Stanford University (https://protege.stanford.edu/publications/ontology_development/ontology101.pdf).
Nowadays, the emphasis is placed on collaboration between subject matter experts and ontology engineers in a working context leveraging an ontology repository, with engineering drivers such as referencing, reuse, modularity and federation.
A more detailed view of the ontology development activities is given in « NeOn methodology for building contextualized ontology networks », M.C. Suarez-Figuero and al., 2008, The NeOn Project:
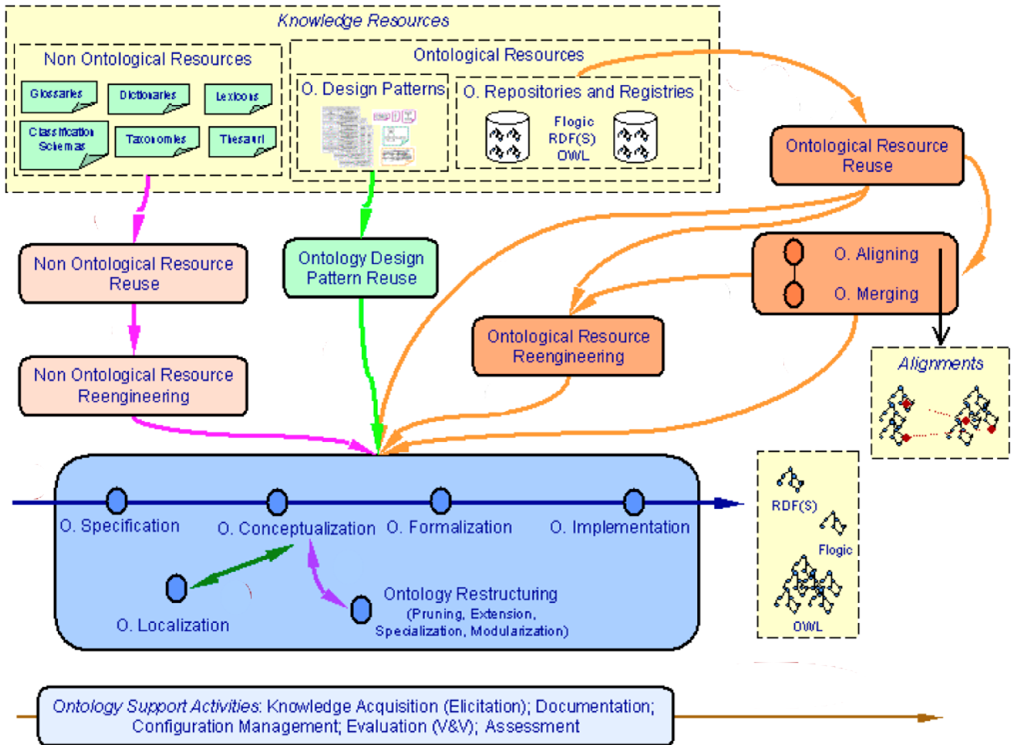
These two proposals can be synthesized into:
- The implementation of a knowledge management context such as a repository for managing available resources as inputs to the engineering activities
- The approach for conceptualizing, formalizing and implementing the resulting ontology
- The use of the repository for explicitly managing the sources and intermediate assets produced during the engineering working model until the production of the resulting ontology as well as managing its future revisions during its maintenance and possible evolutions.
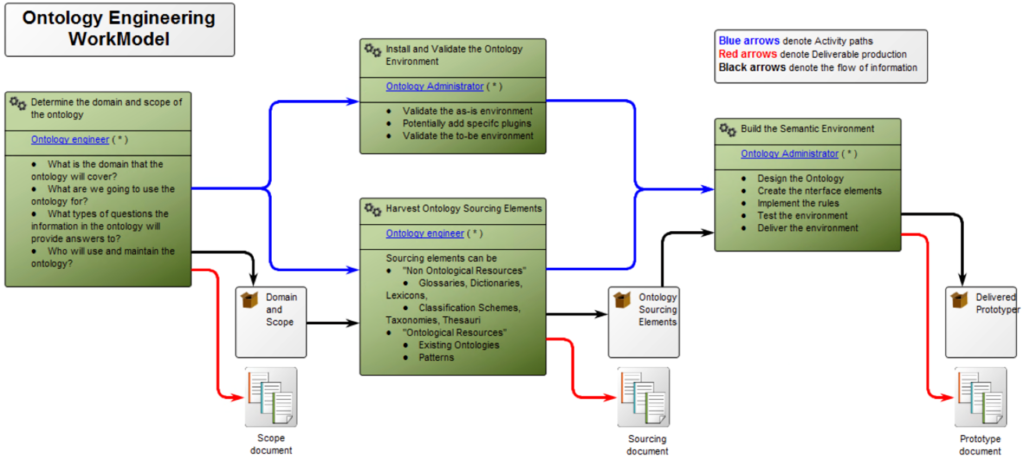
The QualiWare repository environment is naturally the target for implementing this synthesis. Its ability to:
- manage references to external assets,
- model and manage fundamental and standards-based ontologies,
- model and enact approaches using its WorkModel management feature,
leads to implementing these base functions and components to realize this synthesis.
Conclusion
Ontologies are the means to:
- Govern Data knowledge,
- Facilitate harmonization and interoperability across business units,
- Facilitate interoperability at the boundary of the enterprise
Ontologies define the basis for interoperability of data in the Semantic Web.
QualiWare provides the ability to engineer ontology by proposing
- Graphical editing,
- Ontology management,
- Integration within Enterprise Architectures management
Companies can manage foundational and standards-based ontologies in a remote repository dedicated to ontological shared resources, and link their specific ontologies developed in a front repository.
many thanks for theses informations.