
IIRA – Part 1 – Part 2 – References
Part II: Analysis of Key System Concerns
Part I described the several viewpoints and the various functional domains needed to evaluate Industrial Internet Systems. However, there are common concerns that cannot be assigned to a particular viewpoint or functional domain, such as the key system characteristics that we discussed in Chapter 2. Addressing these concerns requires consistent analysis across the viewpoints and concerted system behaviors among the functional domains and components, ensured by engineering processes and assurance programs. We call these key system concerns.
In this part, we highlight a few of these key system concerns in Industrial Internet systems as special topics and provide additional analysis on them. For some of these topics, we summarize their key elements based on prevailing and matured technologies and practices most relevant to Industrial Internet Systems. In others, we introduce some forward-looking ideas bridging what is in place now and what is needed in the near future to support the kind of IISs that we envision. These topics are:
Safety highlights a number of important considerations for safety in IISs.
Security, Trust & Privacy provides additional (to those presented in Part I) details on how to secure IISs end-to-end.
Resilience presents a few ideas on how to establish a resilient system, in reference to some of the learning from the military programs and operations.
Integrability, Interoperability and Composability suggests the direction in which IISs components should be built to support the dynamic evolution of components, including self-assembling components. It also serves as a unifying reference topic for some of the topics, such as Connectivity, Data Management, and Dynamic Composition and Automatic Integration, all of which are to follow.
Connectivity discusses a foundational aspect of Industrial Internet—how to connect the numerous components (sensors, controller, and other systems) together to form IISs.
Data Management concerns the basic approaches for exchanging and management of data among the components in IISs.
Analytics concerns the transformation of vast amounts of data collected in an IIS into information that be used to make decisions and system optimization.
Intelligent and Resilient Control presents a conceptual model and some key ideas on how to build intelligent and resilient control.
Dynamic Composability and Automatic Integration concerns flexible adaptation to optimize services as environments change and to avoid disruptions as components are updated.
8 SAFETY
The Industrial Internet and the systems it comprises manage a variety of safety-critical processes. Safety is a key concern of IISs that must be considered and analyzed throughout their lifecycle. Depending on the operating domain, regulatory requirements may mandate that a target safety assurance level be established for IISs using a risk assessment process. While there are existing safety standards that may apply to IISs under development for different domains (e.g., nuclear, rail, medical, automotive, process, maritime, machinery, and industrial process control), many are based on the fundamentals established in ISO/IEC 61508 Functional Safety of Electrical/Electronic/Programmable Electronic Safety-related Systems and do not explicitly address safety issues related to the cross-cutting concerns, architecture, integration and overall lifecycle of IISs. A complete dissertation of techniques for establishing and meeting IIS safety goals is beyond the scope of this document, but some of the relevant concerns are presented here.
Safety is an emergent property of the system in question and that has two major implications for systems engineering:
- Safety is not compositional: safety of every component in the system does not necessarily imply safety for the system as a whole.
- One cannot predict the safety of a system in a particular situation without first predicting the behavior of the system in that situation.
Therefore, IIS design must focus on not only mandating general notions of safety but also providing mechanisms that enable systems integrators to measure, predict and control the ehavior of the system. For systems integrators to ensure safety, they must understand the intended behavior of the system and at the same time employ mechanisms that can constrain unintended behavior. Safety can be addressed either passively (e.g. by adding guards around a process to make sure nothing escapes the guarded area) or actively (e.g. by adding components that adjust the systems behavior to assure it is safe). Mechanisms include, but are not limited to:
Support for independent functional safety features: A functional safety feature is a feature the rest of the system relies upon to ensure safe operation. Examples include airbags in automobiles, ejection seats in military aircraft, and the automatic shutdown system in nuclear reactors. It is not possible to prescribe specific functional safety features in general because a functional safety feature for one system or context may result in unsafe behavior in another. That being said, each safety-critical IIS must implement the functional safety features necessary to its safety requirements and usage context. Architecturally, functional safety features should be isolated and independent of the rest of the system to the maximum possible extent. This simplifies system safety validation and allows system integrators to mitigate costs associated with ensuring safe system behavior (see subsection “The Role Reliability and Resilience in Safety-Critical Systems” below).
Well-defined, verified and documented interfaces: The system components used in IISs must have well-defined, verified and documented interfaces. Systems integrators can leverage these specifications, and the evidence that demonstrates that components conform to its interface, to make predictions about the emergent behavior of the composite system. Interfaces of concern include software, such as APIs, and relevant physical and processing characteristics that include the resource usage requirements and how the component will behave when used in its intended environment. Component manufacturers should make available any evidence used to verify that a component conforms to its specification. This helps system integrators predict how two or more components may interact when composed.
Enforceable separation of disparate functions and fault containment: Component manufacturers cannot provide complete assurance of component behavior because testing cannot cover all eventualities. Additionally, system integrators may opt to control costs by using components that come with less assurance (providing those components will not be used to support a safety critical function).
Systems integrators must ensure that low assurance components will not negatively impact safety critical system functions. Thus, IIS design must have mechanisms to enforce separation between disparate functions and components. The enforcement mechanism must isolate faults and prevent unintended interactions between different system components. Examples of unintended actions include:
- A software component stealing CPU resources from another.
- A software component corrupting the data or instructions of another.
- A device on the network becomes a “babbling idiot” and preventing other components from communicating in a timely manner.
- A can of liquid on a conveyer spilling and causing the floor near the machine to become slippery, causing a mobile robot to lose traction.
- A motor drawing more power than expected causing a brownout affecting other devices on the same branch circuit.
Runtime monitoring and logging: Engineering is a human activity, and our knowledge of engineering is constantly improving. System failures, when they occur, should be looked upon as an opportunity to learn more. Mechanisms for gathering and preserving the episodic chain of events that has led to a failure may be useful to determine the underlying causes of a particular failure incident. Runtime monitoring and logging is one approach to gather and preserve such information.
In addition to supporting post-accident forensic activities, runtime-monitoring and logging can help prevent accidents. Runtime monitoring can detect if the system under scrutiny has entered or is trending towards an unsafe state and generate an alert. Some systems are equipped with special safety functions that automatically activate a safety mode in response to this alert. These safety modes are designed to either drive the system to a safe state, or prevent the system from entering unsafe states in the first place (e.g., the automatic shutdown system of a nuclear reactor). The runtime monitor can trigger such mode changes.
8.1 RELATIONSHIPS WITH OTHER CONCERNS
Safety interacts with other system concerns.
The role of reliability and resilience in safety-critical systems: Neither ‘reliability’ nor ‘resilience’ imply system safety. Indeed, there can be reliable systems that are unsafe in that they reliably perform unsafe behavior, and there can be unreliable systems that are safe. Even so, reliable and resilient infrastructure is useful and sometimes necessary to support the safety-critical functions of a larger system. Examples of features that support reliability and resiliency include fault tolerant computation and communication, replicated communications, distributed consistency protocols, adaptive control algorithms, and ‘hardened’ components, such as radiation-hardened CPUs and memory. Unfortunately, increased reliability may increase cost. This can be mitigated at the architecture level: The IISs could partition the infrastructure to allow for separation between the infrastructure utilized by safety and non-safety functions. The safety functions reside on a high-reliability (or high-resilience, and high-security) partition while non-safety functions are deployed on a less reliable (but cheaper) partition.
The relationship between safety and security: Often, system safety requirements impose system security requirements. Sometimes safety depends on the presence of a security feature. For example, if a platform cannot protect application code from unauthorized modification, malicious actors can corrupt safety-critical control algorithms and drive the system into an unsafe state. Sometimes, safety depends on the absence of a security feature. For example, one may actually want unauthorized or unauthenticated users, such as emergency responders to have the ability to initiate emergency shutdown procedures. Safety and security requirements (and their possible implementations) must be carefully balanced.
Implications of dynamic composition and automated interoperability for safety: Traditionally, safety-critical systems have been designed, manufactured and integrated by a single systems integrator. This model of integration allows the systems integrator to ensure the safety of their system by decomposing system safety requirements to sub-systems in a top-down manner and by verification and validation to ensure that no unsafe interactions were introduced during integration. Dynamic composition and automated interoperability functionality enable two models of system integration, each with their own set of implications for safety and the IIRA.
Accelerated traditional: Here systems integrators still design, manufacture, and integrate the system prior to its delivery to the customer. The systems integrator understands the top-level system safety requirements and the collection of specific system components that will be composed to comprise the system. In this model, dynamic composition and automated interoperability features, such as active inter-component interface checking, can reduce integration effort by the systems integrator if those features can be trusted. If the dynamic composition and automated interoperability features cannot be trusted, then it would be possible to compose components with incompatible interfaces, and other integration verification activities must be performed by the systems integrator to ensure the system components interact properly with each other. Therefore, if dynamic composition and automated interoperability features are used to support safety-critical functions, those features themselves must be verified and validated to the same level of assurance as the safety critical function.
User assembled: Here component manufacturers market a variety of interoperable components. Users can buy those components and compose them into a system designed to meet the user’s specific needs. Users effectively act as the integrator of these systems. Unlike the traditional integration model, here the integrator (the users) would not have the necessary engineering expertise or resources to ensure the safety of the composite system. Indeed, the user may not even have a comprehensive understanding of the top-level safety requirements for the composite system. Instead, the dynamic composition and interoperability features of both the IIS infrastructure and IIS components must be designed to enforce safe system integration.
9 SECURITY, TRUST AND PRIVACY
To address the concerns of security, trust and privacy in Industrial Internet Systems, end-to-end security capability must be provided to harden endpoints, secure device-to-device communications, enable remote management and monitoring, and secure data distribution. This end-to-end security capability with real-time situational awareness should seamlessly span the functional domains, and the information technology (IT) and operational technology (OT) subsystems and processes without interfering with the operational business processes.
Today, we build IISs with technology from multiple vendors who provide heterogeneous components with various levels of security. This is fertile ground for weak links in the assembled system that must be addressed by building security in by design rather than the often-tried and often-failed paradigm of bringing in security as an afterthought.
Secure design requires establishing the relevant security concerns for endpoints, the communication between them, the management of both the endpoints and the communication mechanisms, and for processing and storing data. The following security concerns must be considered for each of the viewpoints:
- business viewpoint, for an assessment of business risks, cost factors, regulatory and audit requirements, and what is the ROI on security investments,
- usage viewpoint, for a description of security procedures, and of how to secure end-toend activities in an IIS, including privileges assigned to their roles,
- functional viewpoint, for a detailed assessment of security functions required to support end-to-end secure activities and operations and
- implementation viewpoint, for ensuring secure architectures and the best use of relevant security technologies.
Security requirements in each of these viewpoints can be analyzed and addressed separately, but a comprehensive security solution requires considering the interplay between them, for example, how some system designs (implementation viewpoint) need to comply with costs aspects (business viewpoint), or how some security functions (functional viewpoint) may not be appropriate for some end-user requirements (usage viewpoint).
Flaws introduced during the design of IISs can be exploited by hackers and intruders leading to data leakage, business disruption, financial losses and damage to products and company brands. This mandates that security be integrated from the outset with a comprehensive development lifecycle encompassing not only the software design lifecycle, but also hardware design at chip and device level for hardware-backed security, secured physical design (e.g. tamperresistant/proved) for the devices and equipment, and physical plant design along with a robust personnel security program. Each of these requires training and data gathering through the development, deployment and operations of these complex systems.
It is important to keep in mind that security metrics are difficult to define a priori for a system. In order to provide assurance for security the IIS needs to implement security best practices appropriate to the application according to stakeholder policies. Some of the proposed best practices and implementation patterns are described in this section.
To build a comprehensive security solution, the IIS needs to address the following relevant security concerns:
- endpoint security,
- communication security between the endpoints,
- management and monitoring security of both the endpoints and the communication mechanisms and
- data distribution and secure storage.
The following subsections examine each of these concerns.
9.1 ENDPOINT SECURITY
The security of the endpoint is fundamental to the security of the data and control of IISs. The exact nature of the endpoint security is heavily dependent upon the type of endpoints and what interfaces they expose. However, the security measures that are required to protect them share many common security functions. These common security functions can be organized and implemented consistently as self-contained modules that can be deployed in the endpoints to enforce uniform security policies. Once deployed, such a security agent can monitor and perform security management on the activities within an endpoint and its communication with other endpoints.
There are many ways to attack an endpoint and therefore many issues to address. The issues to address include:
- Secure boot attestation
- Separation of security agent
- Endpoint identity
- Endpoint attack response
- Remote policy management
- Logging and event monitoring
- Application sandboxing
- Application whitelisting
- Network whitelisting
- Endpoint and configuration control to prevent unauthorized change to the endpoints
- Dynamically deployed countermeasures
- Remote and automated endpoint update
- Policy orchestration across multiple endpoints
- Peripheral devices management
- Endpoint storage management
- Access control
9.1.1 SECURE BOOT ATTESTATION
An endpoint must start from a known secure state, following only a prescribed boot sequence of steps, with no modification of intended execution function. To ensure this, remote attestation to the integrity of the boot sequence (via the secure agent), as well as policy to describe how to proceed when deviation from the expected boot sequence is detected may be used.
In the event that an endpoint’s boot sequence has been found altered in an unexpected way, the boot process shall fail, and optionally report failure via the secure agent. The endpoint should either be stopped or be quarantined, depending on policy. This ensures that an endpoint that has been tampered with does not participate in the IIS, thus preventing an attack entry point to the overall system.
9.1.2 DEPLOYMENT OF SECURITY AGENT
Four primary security separation models exist to deploy the secure agent at the endpoint: process, container, virtual and physical.
Process-based security agent: If the security agent resides in a process, then it shares the operating environment with other processes. This is the traditional security model, common in the home environment in the form of anti-viruses and miscellaneous security software. This model is well understood and widely implemented, but suffers from severe security weaknesses. For example, if a process on the device is compromised, it may serve as an attack vector for the agent to be compromised. 23
Container-based security agent: The security agent can also be implemented with a secured container within the endpoint. With this approach, the separation is implemented using hardware- and software-enforced boundaries. Container-based security agents include operating system containers (software), Trusted Platform Module, hardware co-processors, secure memory mapping and code execution crypto operations. 24
Virtualization-based security agent: Hypervisors in virtualized environment are widely used to enforce security policies transparently on enterprise and cloud applications in enterprise IT and cloud computing environments. Applied to security management of devices in the OT environment, this approach allows the security agent to function independently in its own environment without changing the existing endpoint functions and its OT operating environment. However, operating within the same physical endpoint as the OT environment does, the security agent gains increased visibility to the activities of the OT environment and is thus able to control security activities such as embedded identity, secure boot attestation, communications (implementing firewall, on-demand VPN connections, mutual authentication, communication authorization, data attestation, IDS/IPS, etc.), all transparent to the OT environment.
Gateway-based security agent: When security cannot be added to an endpoint, as is the case for legacy systems, a security gateway or bump-in-the-wire implementing the security agent function as a physically separate network node can be deployed to secure these type of endpoints and their communications. Because the security agent is not physically on the same endpoint that it protects, advanced security functions such as secure boot attestation or application whitelisting in that endpoint cannot be easily implemented.
9.1.3 ENDPOINT IDENTITY
Endpoints and other controllable assets in an IIS must have a unique identity so they can be managed and tracked via the secure agent. Ideally, this identity is hardware-embedded so that it cannot be altered. Identifiers traditionally used in applications, such as IP address, MAC address, host name Bluetooth address and IMEI, are not sufficiently secure for they can be changed easily and spoofed trivially.
Credentials may be issued to the holder of each identity to prove that its identity is genuine. These credentials, such as cryptographic keys, must be secured by hardware. These measures are required to prevent logical attacks by “impersonating” a legitimate identity, and physical attacks by replacing a genuine asset with a forgery.
9.1.4 ENDPOINT ATTACK RESPONSE
When an endpoint is attacked, it should defend itself, report the attack and reconfigure itself to thwart the attack based on policy. The responsible security management system (see section 9.1.10) should provide the policy to the secure agent in the endpoint in response to the attack, or a priori for use when communication with the server is severed.
Endpoints must remain resilient and secure even when their peer endpoints have been compromised. If an endpoint is able to recognize that a peer has been compromised, it must report the event to the security management system. The security management system should then quarantine that compromised endpoint to contain the damage and diminish the risk of the compromise being spread.
Upon the detection of an attack, an endpoint may increase the level of security monitoring and analysis, and stop suspicious processes and services. As the threat subsides, a decay algorithm slowly should reduce the risk assessment, as appropriate, to bring the system back to the steady state, resetting appropriate policy along the way.
9.1.5 REMOTE POLICY MANAGEMENT
A central security management system defines the configuration of the security controls and functions as a form of a security policy for each endpoint. The security policy is communicated to the secure agent that authenticates and enforces the policy at the endpoint. Policies can be modified and updated to the security agent on-demand to address new vulnerabilities or changing concerns in response to changing circumstances.
9.1.6 LOGGING AND EVENT MONITORING
The security agent must be able to monitor and record events as they occur at the endpoint including events pertinent to security violation, user login/logout, data access, configuration update, application execution and communication.
The endpoint policy defines the events of interest and how specific event records are persisted. This includes location of the storage and the rule for retention to guard against premature deletion of event records. For example, event logs can be stored in a known location on the local file system, or at a remote location that can survive endpoint tampering or failure. The policy should contain provision on access control to prevent unauthorized access and tampering and privacy control to prevent the leaking of personally identifiable information.
9.1.7 APPLICATION WHITELISTING
Mechanisms should be in place at the endpoint to ensure that only known and authorized application code (whitelist) including binaries, scripts, libraries are allowed to execute on the endpoint to prevent the endpoint from being compromised by malicious code. All other execution attempts should be halted, logged and reported. The security management system may update the application whitelist in the policy at the secure agent for its enforcement at the endpoint.
9.1.8 NETWORK WHITELISTING
Mechanisms should be in place at the endpoint to ensure that only a defined set of source/destination, port and protocol tuples is allowed to communicate to/from the endpoint. All other communication attempts should be terminated, logged and reported. Trusted and secured mutual authentication is desirable and required in some cases to prevent masquerading, man-in-the-middle attacks and other network-based attacks. The security management system may update the network whitelist in the policy at the secure agent for its enforcement at the endpoint.
9.1.9 DYNAMICALLY DEPLOYED COUNTERMEASURES
The security management system should be able to deploy trusted new countermeasures and other mitigating controls as part of the endpoint security policy to the security agent for its enforcement at the endpoint.
9.1.10 REMOTE AND AUTOMATED ENDPOINT UPDATE
The security management system must be able to remotely update the endpoint with trusted software updates via the secure agent through an automated and secure process. The firmware and software updates must be first authorized by the security management system before distributing them to the security agents at the endpoints. Upon receiving the updates, the security agents must validate the update based on its policy before allowing them to be implemented at the endpoints.
9.1.11 POLICY ORCHESTRATION ACROSS MULTIPLE ENDPOINTS
Policy orchestration is the coordination of security policy across multiple endpoints to enable secure, trusted operation workflow across these endpoints. For example, a data-generating sensor endpoint and a storage endpoint must have synchronized a consistent policy for the data generated in the former to be stored in the latter.
9.1.12 PERIPHERAL DEVICES MANAGEMENT
Peripherals on an endpoint must be managed based on security policy concerning whether to allow a peripheral to be connected to or disconnected from the endpoint. Any violation of this policy, such as unauthorized removal of a peripheral, may cause the endpoint to be considered compromised and thus subject to quarantine. The security policy should disable by default all communication ports such as USB or other console ports at an endpoint unless they are used for operations. The security agent may allow a port to be opened temporarily for diagnostic purposes, however the port should be closed immediately when it is no longer used.
9.1.13 ENDPOINT STORAGE MANAGEMENT
Data storage and file systems at an endpoint must be managed based on security policy. The security management function includes file integrity monitoring, file reputation tracking (blacklisted, gray-listed, and whitelisted), data, file, file system or device-level encryption, file and data access right management, remote access to file system, data loss prevention, and alerting policy violations reporting.
9.1.14 ACCESS CONTROL
Network access to endpoints must be controlled based on security policy that allows connections required by the operations and deny all other connections. The unauthorized access attempts may be logged and reported to the security management system for analysis. These unauthorized access attempts may be the result of a misconfiguration or an indication of attack that requires appropriate response.
Threats enacted through physical access to endpoints must be considered. Disconnecting power or network cables to an endpoint should not result in vulnerability beyond an endpoint going offline.
9.2 COMMUNICATION SECURITY
In addition to communication solutions with well-known and mature security features, such as Ethernet and IP-based connectivity, industrial systems use an assortment of industrial-specific and often vendor-specific legacy solutions that have limited or no security features. In some cases, a number of legacy communication solutions are used in separate segments of the network where new systems are meshed with legacy ones. Securing communications consistently between legacy endpoints and those using new solutions presents special challenges in IISs.
This section describes how communications between IIS components must be secured, and presents scenarios where security must be considered in the following areas:
- Architectural considerations for information exchange security
- Security in request-response and publish-subscribe communications
- Mutual authentication between endpoints
- Communication authorization
- Identity proxy/consolidation point
- User authentication and authorization
- Encryption communication
9.2.1 ARCHITECTURAL CONSIDERATIONS FOR INFORMATION EXCHANGE SECURITY
When designing security solutions, consideration must be given to requirements in confidentiality, integrity, availability, scalability, resilience, interoperability and performance for both transport layers (the communication transport layer and the connectivity framework, as described in Chapter 12). Protecting communication links at each layer requires corresponding security controls and mechanisms applicable to that layer. An important design question, therefore, is which layers to protect, and how to protect them for a given industrial application. Providing security controls in all layers may be necessary for some applications but may bring unacceptable performance costs for others.
9.2.2 SECURITY IN REQUEST-RESPONSE AND PUBLISH-SUBSCRIBE COMMUNICATIONS
Two common patterns in IIS communications are request-response and publish-subscribe. The request-response pattern is common in industrial systems. Examples of the implementation of this pattern include Java Remote Method Invocation (Java RMI) [6], Web Services/SOAP [7], RPC- over-DDS [8], RESTful Servers, OPC [9], Global Platform Secure Channel Protocol and Modbus [10]. As the protocols of this pattern vary in degrees of support for security, they should be independently and carefully evaluated with regard to confidentiality, integrity and availability requirements. As an example, Modbus, a popular application-level fieldbus protocol within industrial systems, lacks support for authentication and encryption, and does not provide message checksums, and lacks support for suppressing broadcast messages.
Some implementations of the publish-subscribe pattern, such as MQTT or AMQP, rely on an intermediary message broker that performs a store-and-forward function to route messages; others such as DDS may be broker-less. Endpoint security policy should be applied both the publish-subscribe endpoints as well as the message broker (for the former case). For the publish- subscribe pattern the primary categories of threats are: unauthorized subscription, unauthorized publication, removal and replay, tampering and unauthorized access to data.
9.2.3 MUTUAL AUTHENTICATION BETWEEN ENDPOINTS
Endpoints must be able to perform mutual authentication before exchanging data to ensure data are only exchanged with intended parties and not leaked to malicious or unauthorized entities. The security policy may specify the acceptable authentication protocols and credentials to be used for authentication. Resource-constrained devices, such as sensors, may lack the capability to perform cryptographic intensive operations and implement lightweight authentication protocols instead to limit the vulnerability.
9.2.4 COMMUNICATION AUTHORIZATION
Before granting access of any resource, to an authenticated party, authorization must be performed at the endpoint according to the security policy. The security policy may specify finegrain authorization rules such as what data records to share with whom, under what condition (e.g. encryption, anonymization or redaction of certain data fields) including temporal and spatial conditions.
9.2.5 IDENTITY PROXY/CONSOLIDATION POINT
In existing industrial deployments (“brown-field”), the identification of endpoints and their authentication may not be achievable in a way that is consistent with higher security standards. In this case, these components may be proxied by an endpoint with capability that meets the higher standard and capable of performing the proxy functions—the proxying endpoint is referred to as a security gateway (see section 7.2). The security gateway, among other functions, provides identity and authentication proxy functions to these brown-field endpoints enabling them to participate securely in the IIS.
9.2.6 USER AUTHENTICATION AND AUTHORIZATION
In addition to the endpoint credentials, user credentials can be used to identify the user of the endpoint uniquely. This is for authentication and authorization of the user for access to the network and resources at an endpoint. The combination of endpoint and user access control can be used to present a unique access profile to request access to resources at an endpoint.
9.2.7 ENCRYPTION IN COMMUNICATION
Data exchange between endpoints over communication channels must be encrypted with cryptographic keys of security strength and cipher suite meeting the security policy requirements.
9.3 MANAGEMENT AND MONITORING SECURITY
Management and monitoring security involves these areas:
- Identity management
- Provisioning and commissioning
- Security policy management
- Endpoint activation management
- Credential management
- Management console
- Situational awareness
- Remote update
- Management and monitoring resiliency
9.3.1 IDENTITY MANAGEMENT
Hardware-backed identity is required to determine the identity of the endpoint authoritatively. Keys and certificates should be stored in a hardware-secured container (e.g. TPM). These hardware-secured containers generate asymmetric key pairs on chip and never expose private keys outside of the container. They perform crypto-operations on-chip with the private-keys. They export public keys to be distributed to other endpoints or likely signed into PKI certificates by a certificate authority. These containers also perform other crypto-based security operations such as attestation, signing, and sealing on-chip.
9.3.2 PROVISIONING AND COMMISSIONING
An endpoint must be provisioned and commissioned securely before it is allowed to participate in an IIS. In many cases, this process needs to be automated. This requires identity and credentials to be generated, distributed and installed in the endpoints and registered with the security management system.
Endpoint devices receive an identifier either at the time of hardware manufacturing, when the software/firmware image is provisioned to the device or on first boot after that provisioning. Optimally, devices receive an initial set of credentials during a “personalization” step in hardware manufacturing.
Alternatively, devices may generate a credential on first boot then register that credential with a trusted authority; or the device may receive credentials from a trusted authority. The device may register its credentials with additional authorities.
9.3.3 SECURITY POLICY MANAGEMENT
Remote policy management involves policy creation, assignment and distribution. Policies are defined on a security management system and communicated to endpoints via the secure agent.
The agent also ensures that the policy is available to the appropriate processes on the endpoint for configuration and enforcement. The agent may pull the policy, or the policy may be pushed to the agent. The agent may interpret the policy for the security processes on the endpoint.
There may be cases where cross-organizational communication is required; therefore, a common set of interfaces and protocols between the endpoints and the security management system, and even among the endpoints is required.
9.3.4 ENDPOINT ACTIVATION MANAGEMENT
Endpoint activation is the event where a new endpoint is recognized, authenticated and then permitted to exchange data with other endpoints in the system. An endpoint may need to activate with the security management system to be considered a legitimate endpoint in the IIS.
Endpoints should be able to activate dynamically and securely on multiple systems simultaneously, and deactivate as circumstances require.
9.3.5 CREDENTIAL MANAGEMENT
The credential management lifecycle consists of:
- credential provisioning/enrollment/recognition
- additional credential generation (particularly for temporary credentials)
- credential update
- credential revocation/de-recognition
The credentials at an endpoint are managed remotely and securely by one or more security management systems via the secure agent. The endpoint’s credentials can be provisioned, updated and revoked by a security management system, and this should be able to be done automatically for many endpoints at once.
By allowing credentials to be managed by multiple security management systems, the endpoint can be authenticated by multiple IIS networks at the same time. This also requires that one or more certificate authorities can be used on any one endpoint.
There are concerns over using the PKI system (i.e. Certificate Authority Model) [11] for managing large number of endpoints in IISs because of its constraints in scalability and reliability, and complexity in management. New schemes such as the DNS-based Authentication of Named Entities (DANE) [12] are emerging to address some of the scalability, reliability and management issues that associated with existing PKI systems.
9.3.6 MANAGEMENT CONSOLE
The management console allows human user interaction with the security management system for tasks such as creating and managing security policy and monitoring security activities and events across all the endpoints.
9.3.7 SITUATIONAL AWARENESS
The security management system in an IIS must maintain awareness of situations in the network of endpoints including security events, attack attempts, currently deployed mechanisms to thwart such attempts, network health and general endpoint status.
In addition to single-event issues, patterns emerging a sequence of events can contribute to an understanding of the current environment of the IIS. For example, while a single failed login may not be interesting, a series of failed login attempts is significant and contributes to situational awareness. A detection of a single port scan event is not as interesting as a series of events of port scans. By correlating information, the IIS is able to detect system-wide attacks, whereas less coupled systems would miss them.
9.3.8 REMOTE UPDATE
Mechanism must be in place to automatically, securely and remotely update software/firmware via the security agent at the endpoint in response to identified vulnerabilities so they can be remedied quickly.
9.3.9 MANAGEMENT AND MONITORING RESILIENCY
Security management needs to manage and monitor the IIS network especially when facing nonoptimal network conditions such as when it is under attack, degraded or damaged. The communication mechanisms for management and monitoring must continue to function as well as possible, and be able to restore the network to full function with as little manual intervention as possible.
9.4 DATA DISTRIBUTION AND SECURE STORAGE
A core benefit of the Industrial Internet is improving the performance of its operations through data analysis. This process requires the collection of large amounts of data, its analysis in multiple locations and its storage for future use. All these operations must comply with privacy and policy regulations while still providing access to permitted data.
We must therefore consider:
- data security
- data centric policies
- data analysis and privacy
- IT systems and the cloud
9.4.1 DATA SECURITY
Sensitive data in an IIS must be protected during communication (see section 9.2.7) and storage. In the case of storage, sensitive data can be protected by employing data encryption at the field, record, file, directory, file system or storage device level. Access control to the sensitive data must be enforced based on authentication, authorization and access control policy.
9.4.2 DATA CENTRIC POLICIES
Data-centric policies include data security, privacy, integrity and ownership, and these policies apply through all stages, including data collection, distribution, processing and storage. Different actors dictate these security requirements and policies: compliance mandates, such as the Sarbanes-Oxley act; industry standards, such as collecting automotive information; or national security enforcement, to preserve the secrecy of vital parameters in a nuclear reactor.
The information provided by these actors must be translated and implemented automatically to prevent errors.
9.4.3 DATA ANALYSIS AND PRIVACY
To protect sensitive data or meet privacy requirements, data access policy may be provided to enforce fine-grained data access rules for example requiring certain data or fields to be removed, encrypted, obfuscated or redacted before distributing them to the data consumers for analysis or other uses.
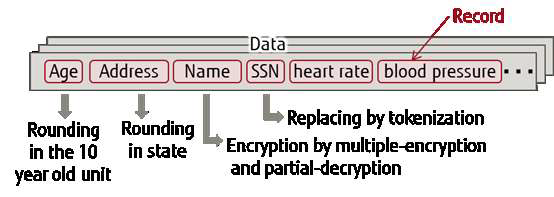
Figure 9-1 Data record encryption, obfuscation or redaction for privacy
The medical record shown in Figure 9-1 requires the enforcement of privacy if it is to be distributed and analyzed by third parties. This is achieved by obfuscation and encrypting at the record level.
9.4.4 IT SYSTEMS AND THE CLOUD
In many cases the storage, distribution and analysis of the data needs to be performed at the IT, as opposed to OT environments. To protect the data, provenance information and privacy requirements should be attached to it so that ownership and the custody chain for the data records can be maintained. This applies during communication, when the data is processed by cloud systems (detached from the industrial system), when the analysis is performed by third parties, or moved to storage environments with different privacy requirements.
10 RESILIENCE
Resilience is more than just recovering quickly from pressure. To be resilient is to be able to take “bitter circumstance in stride” and still “get the job done.” It might cost more or not be done as well had less (intentional or unintentional) adversity been present, but it will be done. Resilience is a superset of fault tolerance—and very much related to autonomic computing notions of selfhealing, self-configuring, self-organizing and self-protecting.25,26
No other institutions are more involved directly in bitter or adversarial circumstances than the military. No other institutions have a greater dependence on resilience of its organizations and operations to survive and to succeed. Therefore, the current thinking of the military on resilience and the lessons they have learned in the past will inform us on how to better effect resilience within Industrial Internet Systems.
Military Command and Control (C2) has four main functions:
Mission planning is either strategic (what resources and programs need to be in place to handle expected major events in the long term), or tactical (what resource can be deployed in response to an event that is expected to occur, and what is the overall impact if the resource is diverted from other tasks). Generally, tactical planning is done by units like ships or battalions and by units at higher levels such as a carrier group or a division) for larger engagements. Tactical planning focuses on a set of objectives such as the enemy’s next moves and planning for those that pose the deadliest threat. For IISs, this is the difference between how we plan to fail (create systems that are robust to expected kinds of failures and have sufficient resources to recover), and how we enable recovery (create subsystems that are aware of their own performance and can adjust how they operate, particularly in light of their peers.)
Situation awareness is knowing what needs to be known about a situation in relation to the tactical plan. Situation understanding is the larger contextual picture: why things are as they are.
Resource Management balances competing interests and concerns. It balances resources between threats that are current and imminent and those that are future and potential. For an IIS, it addresses questions such as how much computational resource to expend against detecting a security incursion vs. increasing replication of a service to assure that some copy will be able to compute a needed result in time.
Decide and Assess is the execution arm and the part that measures what has been done. If one sets out to neutralize an enemy emplacement, places the order and completes an air strike on the target, the next question is whether it has in fact been neutralized. This of course has implications for next steps, which could be further targeting or determining the target is too hardened and change the plan. For an IIS, there will be a constant balance of trying to decide if the current result is ‘good enough’ or if additional resources need to be expended to improve it (such as additional sensor readings to reduce uncertainty, confirmation dialogues to reduce risk of unintended action), or suggesting an in-service part be scrapped after a minor failure as it is more likely to trigger a major failure.
The military generally sorts responsibilities into administration, intelligence, operations, logistics, and communications, all under a common commanding officer. These groups may be replicated at several levels of command, so there may be division level intelligence as well as battalion level (or fleet vs. ship).
Military orders between levels of command have a specific syntax, including a number of sections that must be addressed, but the most important aspect for resilience is the notion of commander’s intent.27 This is used as part of the mission planning process where the commander sets up what the mission is about. The commander’s intent is important to resilience when used operationally, as it enables an isolated unit at any level devoid of communication to still have a chance of knowing what to do even if the extant plan fails.
Example: For instance, if all we have is the order to neutralize hill 73, then we must continue until hill 73 is neutralized or we run out of men. If we instead know that we are told this in the context of getting a clear shot at bunker AAA which is blocked by hill 73, then an unit which is (temporarily) under independent command can look at alternatives; perhaps all that is needed is to suppress the enemy or divert them on hill 73 to give the unit the opportunity to take the shot on AAA. So commander’s intent pushes decision making down to the level that is best able (in terms of having the best information at the best time) to make the decision. Then when the mission is completed, the unit can attempt to reintegrate, report what they did while out of contact and allow the plans to be changed to address the new situation.
This approach handles uncertainty and failures of communication within ‘decide and assess,’ which is probably the most time-sensitive part of command-and-control. When executed well, there is a tremendous amount of flexibility and local negotiation possible even with ‘disconnected’ units to ‘get the job done.’28
Establishing a global information grid (a military cloud) to provide information to the frontline commanders wherever they were has proved to have unintended consequences. For example, providing this information has offered a way to run battles directly from the command headquarters, overriding intermediate command. The military has moved in the other direction in recent years partly because such remote control of battle hurts resiliency. Similarly, moving industrial control to the “cloud” may also hurt resilience—not only does the network itself create an attack surface and a point of failure, but the information available at the scene will always be greater than that which can compressed into the pipe. For resilience, we should instead think of how to improve local decision-making through network services—without introducing new dependencies such as using the cloud for higher-level management and perhaps permission, but not low-level control.
Here then is a list of lessons we can learn from the military C2 structure and doctrine:
Expect to be disconnected from authority. Mechanisms must be in place to allow the mission to succeed, so some level of decision making on the edge is a requirement.
In an IIS, control elements for critical operations must not be dependent on network availability.
Good decisions are not made in a vacuum. Communicate commander’s intent so that units in the field understand show their actions fit the bigger picture. The ability to alter planslocally provides a lot more flexibility and resiliency.
The implication for IISs is that local control elements must know more than just their own part of the plan. They must have a bigger picture of what they are responsible for that allows them to reconfigure their operation and maintain mission-level performance when under stress.
Peer-to-peer communication is more important than hierarchical communication. Changing plans and developing new tasks requires the disconnected units to engage in all parts of commandand-control jointly with their neighbors so they can jointly succeed within the constraints of the commander’s intent. Once that intent (and an initial plan based on the strategically available resources) is communicated, little more needs to be said from higher chain of command until the mission is completed.
In IISs, this suggests that components must be autonomous, and able to act independently based on the plan and information from other independently operating components nearby.
Take advantage of the hierarchical network to optimize all parts of command-and-control. Do not use the connectivity, when available, to centralize decision making but distribute information to ensure that whole network becomes aware of changes to local plans so they can get an early start on changing too.
In IISs, this suggests that components must be aware of the behavior of other components.
Build a system that does not need the network to work—it only needs it to optimize. This is a given in the ‘fog of war.’
In IISs, this partly follows from being able to run disconnected. However, some functions such as safety, should never be compromised just because of a network failure.
Delegate authority but not responsibility. Delegate sufficient authority to the agents to get the tasks done, but assume full responsibility to ensure the tasks are done right.
In IISs, mechanisms must be in place to find the right function for the job, and to validate that it did what it said it would do. It is important, for example, that orchestration elements not just suggest a process, but also suggest how the process can be validated and monitored.
Data without context can never become information. Pushing data around without context is not actionable. Context is hard to transmit as most context is the unwritten aspect of the circumstances and how the data was collected. Again this points to the criticality of ‘man on the spot’ processing—local to where the context actually is, enabling new techniques like learning to discover local phenomena that can help the particular instance of the problem being solved (rather than the much harder problem of inducing broad general rules).
Plans do not survive first contact with the enemy. Many plans are reworked every time we learn something new. To have a plan is not to have a set of instructions for every situation but to ensure training is in place to handle every conceivable contingency. Battles will always be dynamic, what endures is the ability to see patterns, react quickly and get inside the enemy’s OODA loop. 29 685
Control systems observe (by reading sensors), decide (using a comparator) and act (using actuators). There is no ‘orient’ function. In IISs, a resilient control architecture must be able to notice and discover when it is in an unexpected situation (i.e. orient itself), and then work to get itself back into a reasonable operating band, with the cooperation and collaboration of its peers.
Plan and Prepare. Current military thinking tries to go beyond ‘react and respond.’ This goes back to mission planning. We must both plan to fail and enable recovery. We must also capture the lessons learned to aid future recovery. Recovery of prior operational capacity can mean changes to tactics, techniques and procedure (‘doctrine’). That is how the organization learns rather than just individuals.
In IISs, analytics can detect both imminent failure of a component, but also circumstances extant across a fleet of components when a component failed. This enables global learning.
Upward communication is often more important than downward. Mechanisms must be in place to communicate knowledge up the chain of command based on actual incidents, including what has been tried and failed.
In IISs, we have to ensure the kinds of properties driven down to the autonomous edge devices are policies rather than plans. That is, they include advice about how to make choices in difficult situations, rather than specific courses of action. The implication of this is that edge devices are dependent on having appropriate computational elements for the complexity of the kinds of ‘reactive plans’ they are expected to implement. 30
I was just following orders. This is never a legitimate excuse in the military.
In IISs, each component to the extent possible must make sure it does not violate local safety doctrine, even if it means ignoring direct orders from chain of command. 31 The ‘unit on the spot’ is on the spot both in the physical and legal sense.
There is a chain of command. Communications between units must be validated before they are rusted. Obey no commands even if they are issued by a higher-level officer unless they are established in that unit’s chain of command. Trust is established before it is needed, and is necessarily hard to change with very formal proceduresin place for transfer between commands.
Similarly IISs components should be inherently distrustful of ‘changes of ownership,’ ‘new doctrine,’ or even out-of-cycle updates; it is important that they are mechanisms not only for verifying they come from a trusted source, but that they make sense now.
11 INTEGRABILITY, INTEROPERABILITY AND COMPOSABILITY
IISs are assembled from many components from multiple vendors and organizations within a vendor. To be assembled into large systems, these multifarious components must demonstrate: 32
- integrability—the capability to communicate with each other based on compatible means of signaling and protocols,
- interoperability—the capability to exchange information with each other based on common conceptual models and interpretation of information in context and
- composability—the capability of a component to interact with any other component in a recombinant fashion to satisfy requirements based on the expectation of the behaviors of the interacting parties.
Composability relies on and adds to interoperability and integrability. Integrated components may have a capacity to communicate with each other but there is no guarantee that they can exchange information correctly, let alone whether they would have the intuitively expected behavior. Interoperable components can exchange information correctly but there is no guarantee their behavior is predictable. To look at this in another way: if an integrable component is replaced with another integrable component, the system may stop functioning; if an interoperable component is replaced, the system may behave quite differently; if a composable component is replaced with another with similar specifications, the system behaves in the same way.
Example: Two people are integrable if both are able to speak and listen; interoperable if they speak the same language; and composable if they share similar culture and educational background and can collaborate for specific tasks.
Consider a person as a potential pilot in an airplane cockpit. The person is considered integrable with the airplane cockpit if she fits well in the seat, can view the front horizon, see the instrument readings and indicators, and reach to all the controls—this includes any physically fitting adult. The same person is interoperable with the cockpit if she understands the meaning of the instruments and the intended outcome of the controls—this includes any physically fitting enthusiast about piloting. The same person is composable with the airplane cockpit if she is trained for the model of the airplane so that she understands the meaning of the instruments in context and the behavior of the airplane when she exercises control over it. One appropriately trained pilot can replace another in operating a plane.
IISs are large in scale and constructed from many types of components that are each evolving at an increasingly rapid pace. Components will change from being automatic (working by themselves with little or no direct human control) to autonomous (having the freedom to act independently) and they will need to be able to self-assemble. Integrability and interoperability are inadequate to meet the needs of such systems. We also need composability.
Human interaction and communication using natural languages has proven to be a robust and dynamic method for composability. This is evident from observing how well two strangers can communicate on the spot, with minimal preparation for integration and interoperation, and how well they form groups collaborating to complete large tasks (or gossiping on Facebook).
Willingly or not, component designers have different models of reality with different constraints and assumptions. Lacking telepathy or shared memory between designers of different components means models, constraints and assumptions are not easily communicated or shared. It is therefore difficult to support the higher levels of communications and interactions beyond the level of integrability.
Facing this challenge, we impose a mental framework for undertaking integrability, interoperability, and composability as different levels of communication or interaction, similar to that taken in Conceptual Interoperability [13], an idea grounded in simulation theory—how to make different parts of a simulation system interoperate.33
We treat each communication in terms of passing messages containing symbols, similar in concept to natural language. (We will use natural language for examples.) The manner of communication supporting integrability in messages is well understood, so we focus on interoperability and composability.
At the base level, we have vocabulary and syntax—grammar—rules on legal word order and the relationship to meaning. For example, “car race” and “race car” both use the same words, and the meanings of the words themselves to do not change, but the thing that is denoted by the two examples, which differ only in their syntax, is different. Syntax can be fixed, as they are for the order of entries in a form, or variable as they are in a sentence where grammar is expressed as a set of rules.
The next level up is semantics—the meaning of the words themselves. In most languages, each word can have more than one sense, which is taken up by context. For example, “Safety” has one meaning in an industrial setting and another in football; we would not expect a safety engineer to worry about a defensive strategy in a game. Typically, in systems design we try to have each symbol have a unique context-free meaning, but this can also lead to excessive verbosity as well as inflexibility.
Database schemas tend to express the semantics of items in the structure of records, and these can be used as a kind of translation between different systems. For example, one database may talk about ‘names’ while another may segregate ‘last name’ and ‘first name’ but the meaning of ‘last name’ is culturally dependent, so translating between the two may depend on the culture of the person being denoted. In one culture, the ‘last name’ is given; in another, it is that of the family.
Therefore, to exchange information with natural languages, we need to share some basic vocabulary (how a word is interpreted in different contexts) and syntax in which the words can be arranged into structures. This semantic understanding in communication is the basis of interoperability.
Next, we have pragmatics, which is the meaning of a sentence in context. This generally depends on the conceptual model of the world. Pragmatics allows us to understand the import of an utterance on a particular occasion. In speech act [14] theory (how speech can be treated as a form of action), the base level is the ‘locution’ or what was actually said—the grunts in the utterance along with the syntax and semantics that are defined by the language (as opposed to the use in this instance). Above that is the ‘illocution’ or what the speaker intended to say: the pragmatics. 34 The final layer is the ‘perlocution,’ which is the effect (intended or otherwise) on the other parties who hear the locution.
So one way to think about communication is that we want to specify the illocution (what we intend to say) such that the perlocution (the effect on the listener) can be what we intend. (‘Can be’ rather than ‘will be’ because the speaker does not control the mental state of the listener, and the listener may not use the locution for the speaker’s intended purposes—let’s recall the ‘invented the internet’ meme among others.)
Therefore, to exchange information with natural languages to achieve the intended effect, we need:
- to share a common or similar world knowledge (the understanding of the natural world and culture),
- the conceptual model, to have the ability of comprehend the meaning in its context (locution and illocution) and
- some general expectation of the other party in their understanding of the information (illocution) and their reaction (perlocution)—behavior.
This pragmatic understanding is the basis for composability.
With this understanding of the different ways components can be assembled to form larger systems and how they are related to the different levels of understanding in communications, we can point to the places in this document where each of these elements are addressed:
Levels of Communication Levels of understanding in communication35 Refer to
Integrability
Technical
Connectivity (Chapter 12)
Interoperability
Syntax—getting the format of the messages right
Semantics—getting the meaning of the symbols in the messages right
Connectivity (Chapter 12) and Data Management (Chapter 13)
Composability
Pragmatics/illocution—interpreting what was intended by the sender
Intelligent and Resilient Control (Chapter 15), Safety (Chapter 8), and Dynamic Composition and Automatic Integration (Chapter 16)
Table 11-1 Mapping of Levels of Communication to topics in this document
12 CONNECTIVITY
Ubiquitous connectivity is one of the key foundational technology advances that enable the Industrial Internet. The seven-layer Open Systems Interconnect (OSI) Model [15] and the fourlayer Internet Model [16] do not adequately represent all Industrial Internet connectivity requirements. An Industrial Internet System is more complex and it is necessary to define a new connectivity functional layer model that addresses its distributed industrial sensors, controllers, devices, gateways and other systems.
12.1 ARCHITECTURAL ROLE
Connectivity provides the foundational capability among endpoints to facilitate component integration, interoperability and composability (see Chapter 11).
Technical interoperability is the ability to exchange bits and bytes using an information exchange infrastructure and an unambiguously defined underlying networks and protocols. Syntactic interoperability is the ability to exchange information in a common data format, with a common protocol to structure the data and an unambiguously defined format for the information exchange. Syntactic interoperability requires technical interoperability.
For IISs, connectivity comprises two functional layers:
- Communication Transport layer—provides the means of carrying information between endpoints. Its role is to provide technical interoperability between endpoints participating in an information exchange. This function corresponds to layers 1 (physical) through 4 (transport) of the OSI conceptual model or the bottom three layers of the Internet model (See Table 12-1).
- Connectivity Framework layer—facilitates how information is unambiguously structured and parsed by the endpoints. Its role is to provide the mechanisms to realize syntactic interoperability between endpoints. Familiar examples include data structures in programming languages and schemas for databases. This function spans layers 5 (session) through 7 (application) of the OSI conceptual model or the Application layer of the Internet Model (See Table 12-1).
The data services framework in the data management crosscutting function builds on the foundation provided by the connectivity framework to achieve syntactic interoperability between endpoints. That, in turn, provides the foundation for semantic interoperability required by the “Dynamic Composition and Automated Interoperability” as discussed in Chapter 16.
The table below summarizes the role and scope of the Connectivity functional layers
Scope of IIC Reference Architecture Crosscutting Function
Correspondence to OSI Reference Model (ISO/IEC 7498) [15]
Correspondence to Internet Model (RFC 1122) [16]
Correspondence to Levels of Conceptual Interoperability [13]
Connectivity Framework Layer
7. Application 6. Presentation 5. Session
Application Layer
Syntactic Interoperability Mechanism introduces a common structure to exchange information. On this level, a common protocol to structure the data is used; the format of the information exchange is unambiguously defined.
Communication Transport Layer
4. Transport Transport Layer Technical Interoperability: provides the communication protocols for exchanging data between participating systems.
On this level, a communication infrastructure is established allowing systems to exchange bits and bytes, and the underlying networks and protocols are unambiguously defined. 3. Network Internet Layer 2. Data Link Link Layer 1. Physical
Table 12-1 Role and scope of the connectivity functional layers
12.2 KEY SYSTEM CHARACTERISTICS
In IISs, the connectivity function supports several key characteristics:
Performance: High performance connectivity is expected in IISs. The spectrum of performance ranges from tight sub-millisecond control loops to supervisory control on a human scale. The performance characteristic is measured along two axes.
- Latency and jitter: The right answer delivered too late is often the wrong answer. Thus, latency must be within limits and low jitter is needed for predictable performance.
- Throughput: High throughput is needed when large volumes of information are exchanged over a short time.
High throughput and low latency are often competing requirements. Low latency and jitter are often more critical than throughput because IISs require short reaction times and tight coordination to maintain effective control over the real-world processes.
Scalability: Large numbers of things in the physical world and endpoints that exchange information about those things must be represented and managed. The connectivity function must support horizontal scaling as billions of things are added into the system.
Resilience: IISs operate continually in a real-world environment prone to failures. Endpoints operate in a dynamic fashion and may fail or become disconnected. Connectivity should support graceful degradation, including localizing the loss of information exchange to disconnected endpoints and restoring information exchange automatically when a broken connection is restored.
Connectivity security—architectural considerations: Information exchange among different actors within a system takes place over the two abstract layers documented in Table 12-1, both of which must consider when designing security solutions, including those of confidentiality, Integrity, availability, scalability, resilience, interoperability and performance.
Different information exchange patterns used in the connectivity framework, such as requestresponse or publish-subscribe patterns, have different security requirements.
Connectivity Security—building blocks: Information exchange security among connectivity endpoints relies on:
- explicit endpoint information exchange policies
- cryptographically strong mutual authentication between endpoints
- authorization mechanisms that enforce access control rules derived from the policy, and
- cryptographically backed mechanisms for ensuring confidentiality, integrity, and freshness of the exchanged information.
A security management mechanism manages the information exchange policies for connectivity endpoints. They define how to protect exchanged information. For example, they specify how to filter and route traffic, how to protect exchanged data and metadata (authenticate or encryptthen-authenticate) and what access control rules should be used.
Longevity: IISs have long lifetimes, yet components, especially those in the communication transport layer, are often built into the hardware and hence are not easily replaceable. Where feasible, the connectivity software components should support incremental evolution including upgrades, addition and removal of components. It should also support incremental evolution of the information exchange solutions during the lifecycle of a system.
Integrability, interoperability and composability: IISs comprise components that are often systems in their own right. Connectivity must support the integrability, interoperability and composability of system components (see Chapter 11), isolation and encapsulation of information exchanges internal to a system component, and hierarchical organization of information exchanges. In dynamic systems, connectivity should also support discovery of system components and relevant information exchanges for system composition.
Operation: IISs generally require maintaining continuous operation (see Section 6.3). Hence, it must be possible to monitor, manage and dynamically replace elements of the Connectivity function. Monitoring may include health, performance, and service level characteristics of the connectivity function; management may include configuring and administering the capabilities; dynamic replacement may include being able to replace hardware and or software while a system is operating.
12.3 KEY FUNCTIONAL CHARACTERISTICS OF THE CONNECTIVITY FRAMEWORK LAYER
The connectivity framework layer provides a logical information exchange service to the endpoints participating in an information exchange. It can observe and ‘understand’ the information exchanges, and use that knowledge to improve information delivery. It is a logical functional layer on top of the communication transport layer and should be agnostic to the technologies used to implement communication transports.
The key role of the connectivity framework is to provide syntactic interoperability among the endpoints. Information is structured in a common and unambiguous data format, independent of endpoint implementation, and decoupled from the hardware and programming platform. The connectivity framework addresses service discovery, information exchange patterns (such as peer-to-peer, client-server, publish-subscribe), data quality of service, and the programming model.
Discovery and permissions: To support more intelligent decisions, the discovery, authentication and access to services (including information exchanges) must be automated.
A connectivity framework should provide mechanisms to discover:
- The services available and their associated required or offered quality of service
- The data formats associated with the services
- The endpoints participating in an information exchange
The connectivity framework discovery mechanisms should provide a means to:
- Authenticate endpoints before allowing them to participate in an information exchange
- Authorize permissions (e.g. read, write) granted to the endpoints participating in an information exchange
Data exchange patterns: A connectivity framework should support the following information exchange patterns, typical of IIS.
- Peer-to-peer is a symmetric information exchange pattern between endpoints without any intermediary or broker. It can provide the lowest latency and jitter information exchange between endpoints.
- Client-server is an asymmetric information exchange where endpoints are classified into “client” or “server” roles. A “client” can initiate a service request that is fulfilled by endpoints in the “server” role. An endpoint may operate in both a client and a server role. This pattern is sometimes also referred to as a “pull” or a “request-reply”, or a “requestresponse” style pattern.
- Publish-subscribe is an information exchange pattern where endpoints are classified into “publishers” or “subscribers”. A publisher can “publish” information on a well-known topic without regard for subscribers. A subscriber can “subscribe” to information from the well-known topic without regards for publishers. Thus, the topic acts as a channel that decouples the publishers form the subscribers. The result is loosely coupled endpoints that can be replaced independently on one another. An endpoint may operate in both a publisher and subscriber role. This pattern is sometimes also referred to as a “push” style pattern.
Data quality of service: Different information exchanges have varying requirements on how the information is delivered. This non-functional aspect of the information exchange is referred to as the quality of service (QoS).
A connectivity framework should support many of the following information exchange QoS, ategories.
Delivery refers to the delivery aspects of the information. These include
- At most once delivery: Variations include fire-and-forget or best efforts delivery, and “latest update” delivery. This is typical of state updates.
- At least once delivery, sometimes also referred to as reliable delivery. This is typical of events and notifications.
- Exactly once delivery: This is typical of job dispatching, and sometimes referred to as “once and only-once” delivery.
Timeliness refers to the ability of the connectivity framework to prioritize one type of information over another, and inform the endpoints when the delivered information is “late”.
Ordering refers to the ability of the connectivity framework to present in the information in the order it was produced, or received, and collate updates from different things in the system.
Durability refers to the ability of the connectivity framework to make information available to late joiners, expire stale information, and extend the lifecycle of the information beyond that of the source when so desired, and survive failures in the infrastructure.
Lifespan refers to the ability of the connectivity framework to expire stale information.
Fault Tolerance refers to the ability of the connectivity framework to ensure that redundant connectivity endpoints are properly managed, and appropriate failover mechanisms are in place when an endpoint or a connection is lost.
Security refers to the ability of the connectivity framework to ensure confidentiality, integrity, authenticity and non-repudiation of the information exchange, when so desired.
The connectivity function’s performance and scalability limits would ultimately be determined by the communication transports layer. Therefore, the connectivity framework layer must introduce minimal overhead in providing the information exchange QoS and must have minimal impact on the overall performance and scalability.
Programming Model: IISs typically involve multiple components, developed by multiple parties over time, with a variety of programming languages.
A connectivity framework must provide an un-ambiguously documented programming model, in multiple programming languages, commonly used in the different parts of an IIS, such as C/C++, Java, C# and so on.
12.4 KEY FUNCTIONAL CHARACTERISTICS OF THE COMMUNICATION TRANSPORT LAYER
The communication transport layer transparently provides technical interoperability among the endpoints. The communication transport must address endpoint addressing; modes of communication; network topology, whether endpoints will be connected in a virtual circuit or connectionless, mechanisms to deal with congestion such as prioritization and segmentation, and with timing and synchronization between endpoints.
Network addressing: Each node in an IIS can house one or more components, each with one or more connectivity endpoints. Each node is identified by an address that can be locally unique and possibly globally unique. A node, and hence the endpoints residing on it, may be reachable via multiple addresses. The addressing scheme and associated infrastructure should be able to support billions of devices.
Communication modes: A communication transport can support one or more of the following communication modes:
- Unicast for on-to-one communication between two endpoints
- Multicast for one-to-many communication between endpoints
- Broadcast for one-to-all communication between endpoints, where “all” refers to all the endpoints present on the communication transport network at the time of transmission.
Topology: Communication transport may have one of the network topologies below:
- point-to-point
- hubs-and-spoke
- meshed
- hierarchical
- a combination of the above
It does not preclude others.
Communication transport gateways (see below) can be used to link multiple networks and communication topologies, to form more complex topologies.
Span: A communication transport network in the logical architecture view may span across multiple physical geographies. In the physical view, a logical communication transport network may span just the local area (LAN), or span across large geographic distances (WAN), or span somewhere in between (MAN).
Connectedness: For interactions between endpoints that require high degree of scalability, low latency and jitter, the design of connectivity function should give careful consideration to the choice of connection-oriented and connectionless mode of communication transport and its specific implementation. For example, UDP as a connectionless communication transport is usually chosen for low latency and jitter applications in typical network settings in comparison to TCP as its connection-oriented counterpart, largely due to the retransmission delay and other overheads in TCP. On the other hand, in a network with complex topology and high variation of traffic loads, connection-oriented communication transport may offer less jitter by providing a “virtual circuit” behavior that reduces the variation in routing path.
IISs call for new connection-oriented communication transports that do not suffer the drawbacks that are found in TCP today. When using a connectionless communication transport, the connectivity framework design needs to handle failures in the transport caused, for example, by loss of or out of order packets. Consequently, designing a connectivity framework based on the connection-oriented transport may preclude it from providing a connection-less information exchange.
Prioritization: IISs often need a way to ensure that critical information is delivered first, ahead of non-critical information. The communication transport function may provide the ability to prioritize some byte sequences over others in the information exchange between endpoints.
Network Segmentation: IISs often need a way to separate information from different functional domains over the same communication transport network. The communication transport function may provide the ability to segment a communication transport network, to isolate different functional domains and to isolate one set of information exchanges from another.
Timing & Synchronization: IISs often need a way to synchronize local endpoint clocks over a communication transport network. Many methods are in use today, including NTP or PTP based time synchronization and GPS clocks, and new approaches are in development. The communication transport function may provide ability to synchronize time across the network.
12.5 CONNECTIVITY GATEWAYS
IISs need to integrate multiple technologies, and in the system’s lifetime, new connectivity technologies may need to be integrated as well. Gateways can be used to bridge one or more connectivity technologies. This gateway concept is shown in the figure below.
Figure 12-1 Connectivity Gateway Concept. A connectivity core standard technology (baseline) is one that can satisfy all of the connectivity requirements. Gateways provide two functions (1) integrate other connectivity technologies used within a functional domain, (2) interface with connectivity technologies in other functional domains.
To keep the reference architecture manageable, within a functional domain, a connectivity technology standard is chosen as the baseline, and referred to as the “connectivity core standard”. Gateways are used to bridge other technologies and to the connectivity core standards used in other functional domains.
There are two types of commonly deployed connectivity gateways:
- Communication transport gateways expand the logical span of communications across transport networks. They are transparent to the payload and do not make any logical changes to the payload.
- Connectivity framework gateways expand the logical span of connectivity across connectivity framework technologies. They preserve the logical structure of data, but may change the representation (e.g. binary format vs. string format).
Connectivity gateways provide the architectural construct to incorporate new connectivity technologies that will become relevant in the future. They allow the possibility to pivot to a new baseline core standard that better satisfies the requirements, thus providing a stable foundation anchored in “best-of-breed” technologies available today, while allowing for future evolution.
13 DATA MANAGEMENT
Industrial Internet Systems Data Management consists of coordinated activities involving tasks and roles from the usage viewpoint and functional components from the functional viewpoint, specifically:
- Reduction and Analytics
- Publish and Subscribe
- Query
- Storage, Persistence and Retrieval
- Integration
- Description and Presence
- Data Framework
- Rights Management
13.1 REDUCTION AND ANALYTICS
Sensors and other systems in the IIS produce extremely large amounts of data. 36 Transmitting all this raw data over the networks to a central data center is often unnecessary and prohibitively expensive, but insights contained in the raw data must not be lost.
Reduction and analytics can manage data by either reducing the volume or velocity without losing the value or the information content. It is analogous to lossy data compression, as the original IIS data is irretrievable.
Analytics summarize raw data and produce an approximation of the truth that is suitable for downstream communication, processing and storage, while data sampling and filtering are examples of data reduction techniques devoid of analytics. Data reduction and analytics services suggest a migration of computing, networking and storage resources from enterprise to edge systems.
13.2 PUBLISH AND SUBSCRIBE
Publish and subscribe is suited for exchanging data updates between loosely coupled components and allows the publish-subscribe framework to optimize the communication path between publishers and subscribers based on their requirements.
Publish-subscribe contributes to IIS reliability, maintenance and resilience by the decoupling of publishing and subscribing components in both location (location transparency) and time (asynchronous delivery). This decreases the likelihood of fault-propagation and simplifies incremental updating and evolution. Interactions on the receiver side can be periodic (time- driven) or responsive (event-driven), depending on the needs of the user. Asynchronous transfers can also handle IIS component failures such as a network failure on the data path by delaying rather than cancelling an ongoing data transfer operation.
Publish-subscribe naturally supports the following kinds of IIS data exchange.
Streaming data: Data is continually or periodically updated at fixed rates ranging from KHz frequencies to multi-second periods, requiring low latencies and jitter with best-effort reliability. Components often check for the reception of data on a periodic basis. When the volume of streaming data is exceedingly large, publish-subscribe offers key advantages for the large numbers of interconnected systems.
Alarm and event: Data is issued when detection of specific IIS system conditions occurs. This spontaneous publication requires the IIS system to provide at a minimum guaranteed at-leastonce delivery. IIS alarm and event data should be delivered with low latency and high priority, and pre-empt lower priority data where needed to ensure critical alarms are transmitted within acceptable delays. Parallel processing of a topic by multiple subscribers is essential when large number of spontaneous alarms or events may arrive at once.
Command and control: Control algorithms or people change the behavior or state of IIS components by generating command and control messages. They are typically time sensitive and require delivery by a deadline to allow target IIS component to react in a timely manner. Spontaneous publication is the norm and it requires guaranteed, low-latency and high-priority delivery, pre-empting lower priority data where needed, to minimize response time.
Configuration: Configuration or policy data are exchanged to enable IIS components to adjust their algorithms and behavior. These data change slowly, and typically have low latency and low priority requirements. Persistence is essential to support information requirements of newly joining subscribers even when the original moment of publication is missed. The data may also need to persist beyond the lifetime of the original publisher.
Publish-subscribe serves these purposes:
- Reliable data flow from the edge to a data consolidation and aggregation tier, for example to a cloud-based data services platform.
- Scalable handling of a large, evolving number of data sources such as devices, as well as of a large number of data consumers.
- End-user, application-level data consumption often requires a subscription model, from data consolidated on a platform to application components.
- Reliable control flow from applications or management services to devices: Control commands can be multi-cast in a way that allows devices to get these commands whenever they are ready.
13.3 QUERY
IISs employ two models to make queries. The one-time query model is associated with traditional databases and it fits well with the request-response pattern. The continuous query model is associated with data stream management systems and in-memory databases. It fits naturally with a publish-subscribe pattern and is better suited to handle infinite and rapidly changing data streams and support real-time analytics.
IISs use a combination of two styles to select a subset of data from a larger data set: Save Data; Run Query and its inverse, Save Query; Run Data. 37 Both query styles and models may apply at different levels in an IIS architecture, including at the device level.
Addressable devices may support direct queries (e.g. using WebSockets) in pull mode. Alternatively, device data may be pushed to a gateway configured with filtering rules that selects a subset of the device-generated data stream before acting as a data source to a higher-level data broker or data bus.
Query serves the following purposes:
- selection of a subset of device-generated data, either pulled by requests to addressable devices or pushed to a gateway running filters, and
- selective, usage-centric access to consolidated data by end-users and analytics, possibly in the cloud
13.4 STORAGE, PERSISTENCE AND RETRIEVAL
Storage, persistence and retrieval support many IIS functions:
Record supports defining and persisting a subset of IIS data in sequential order. Preserving timestamping information supports ordering identification and reproduction between different data sets. Record data is typically not queried or reproduced as a time-series. Record is used for meeting record-keeping obligations, post-processing and analysis, replaying of system scenarios and related II use cases.
Replay supports retrieving a collection of IIS data previously recorded by replaying data-items in the order received. Replay supports creating simulation environments, regression tests and related II use cases.
Historian persists selected data for delayed time-series analysis.
Big data solutions support voluminous IIS Control Domain system data.
Storage, persistence and retrieval serve these purposes:
- creation of audit records for future auditing (record and historian)
- support for simulations and various forms of testing (record and replay) and
- reliable storage and scalable archiving (Big Data).
13.5 INTEGRATION
Subsystems often have only partially compatible data models, so integration mechanisms between them are essential. An IIS Integration mechanism may use a wide variety of available integration mechanisms, including:
Syntactical transformation, which requires knowledge about the structure of the data and transformation rules in both IIS subsystems. Presence Discovery (see below) partially addresses this requirement. Semantic compatibility is also required and can be achieved via an Open Standards based metadata solution such as ISO 11179.
Domain transformation, which converts a data domain based on one protocol to a data domain based on another.
Integration serves these purposes:
- enabling integration across various middleware and application components and
- supporting functions analogous to conventional ETL, typically occurring in the first stages of data transfer, and preceding initial storage. 38
13.6 DESCRIPTION AND PRESENCE
Description and presence enable components to discover the kinds, format, structure and metadata of available system data. Both use a variety of available mechanisms including query.
Presence allows components to discover which kinds of data are available using mechanisms such as query.
Metadata description enables components to obtain definitions of the structure of, and other information about, the present data.
Description and presence serve the following purposes:
- dynamic integration of new application components or middleware in a deployed IIS,
- addition of new types of devices with different data models and communication modes,
- design of a system management console applicable to various IISs and
- composition of IIS with different data models.
13.7 DATA FRAMEWORK
Data frameworks provide users with insight into state and behavior of data exchange components by exposing diagnostic data, such as data update rates, number of discovered framework participants and detected message loss. Diagnostic data is similar to other data and therefore subject to all regular data mechanisms.
Monitoring and analyzing framework-associated information access is required such as data exposed by ‘description and presence’. Framework mechanisms produce regular data that should be accessible via ‘publish, subscribe and query’. The data provided enables creation of a dashboard for the data management framework that can track:
Component presence discovery identifies IIS component past or present framework participation.
Component activity monitoring monitors IIS component data such as update frequencies, throughput numbers, CPU load and memory usage.
Traffic monitoring monitors data flow characteristics such as data exchange volume, throughput, latencies, and jitters.
Data frameworks serve these purposes:
- design of a system management console applicable to various IIS and not specific to system technologies and components and
- ongoing deployed IIS testing and diagnostics
13.8 RIGHTS MANAGEMENT
IIS data rights management identifies and tracks data ownership. Rights management enables data owners to grant use rights, manage access based on the granted rights, and protect against unauthorized use. Rights management must be built on security functions but are clearly distinct from generic data protection and privacy.
Rights management serves these purposes:
- general data stewardship, in particular in case of consolidation and integration scenarios (between IISs, or IIS integration with enterprise systems),
- out-sourcing of data-related functions of an IIS to third parties such as cloud providers and
- support for regulatory and compliance requirements.
14 ANALYTICS AND ADVANCED DATA PROCESSING
Analytics and advanced data processing transform and analyze massive amounts of data from sensors to extract useful information that can deliver specific functions, give operators insightful information and recommendations, and enable real-time business and operational decisions, as shown in Figure 14-1. This section discusses the middle two boxes: advanced data processing in a system outcomes flow.
Figure 14-1 Advanced Data Processing in a System Outcomes flow
14.1 ADVANCED DATA PROCESSING
Advanced data processing enables a better understanding of system operational states and environments. It identifies and analyzes emerging information patterns to enable control system assessments under varied conditions in different environments. These assessments improve functionality and reduce operational cost and negative effects. For example, they enable utility companies to optimize electricity level output based on dynamic usage patterns that factor in weather, season, events, pricing, resource availability, cost and electricity generation asset availability; support vehicle and equipment fleet management; optimize smart home energy management and other unimagined capabilities. This is called dynamic operations optimization.
Advanced data processing can also optimize system missions. For example, metropolitan area real-time traffic pattern analysis combined with roadway conditions, roadway construction and maintenance, weather condition, time and day, seasons, accidents and other events can lead to vehicle control systems determining optimal routes to reduce travel time, congestion, pollution and energy consumption.
Industrial Internet advanced data processing consists of a number of components, with the two primary disciplines being complex event processing and advanced analytics. They share a common objective in discovering meaningful patterns from data.
Complex event processing receives streaming data from disparate sources to detect, abstract, filter and aggregate event-patterns, and finally to correlate and model them to detect event relationships, such as causality, membership, and timing characteristics. By identifying meaningful events and inferring patterns that suggest large and more complex correlations, proper responses can be made to these events and circumstances.
Advanced analytics are used to discover and communicate meaningful patterns in data and to predict outcomes. Traditional business analytics are typically applied to business data to describe, predict and improve business performance.
Advanced data processing can reside in various components in an IIS across the breadth of its Functional Domains. It may, for example, be implemented in the information domain to analyze data aggregated from the control domain, other functional domains and external sources to providing analytic results covering the full scope of an end-to-end IIS. It may also be implemented in the control domain to analyze data to realize functionality in a local scope.
14.2 ADVANCED DATA PROCESSING PATTERN AND PROPERTIES
Advanced data processing can be implemented according to a variety of architectural patterns. One common architecture is a pipes and filters architecture [17] that allows pipelines to be created, in parallel and series, based on the application requirements, as depicted in Figure 14-2.
The value in this composability is two-fold:
- the problem is divided into parts where each can be solved independently, to support different requirements and
- pipelines need not be co-located allowing the processing to be deployed as appropriate.
Figure 14-2 Analytics Pipeline Functionality [18]
Two components enable change over time. A dispatcher directs the input to the relevant analytics pipeline(s) that supply an environment in which data is analyzed and stored, and clients either pull data from a pipeline (as a query), or have data pushed to them (a notification).
A pipeline feeds the dispatcher with data, composed with other pipelines that tap into these data streams. Each analytics pipeline has a model set of features:
- ingress: connected to the dispatcher with the responsibility to transform the incoming data stream into something the storage component can handle,
- storage: temporary or long-term resource, such as a buffer, memory, disk, storage cluster, distributed file system that makes the data available to other components,
- analytics: configured with algorithmic functionality, which is designed using the engineering interface ,
- outgress: responsible for exposing the pipeline results,
- Scheduler: manages concurrent access to storage and schedules the analytics tasks,
- engineering interface: design time environment for specifying and experimenting with analytics algorithms, and
- client interface: provides access the data, including analytics results.
Each pipeline should have an ingress and egress specification defining compatibility criteria for the dispatcher and other pipelines, and a quality-of-service specification setting response-time expectations.
To match defined application needs, each pipeline type’s properties must be understood.
Property Description
Data Flexibility New/unknown data types, without data model modification
Algorithm Flexibility Variety of supporting libraries, query representations
Productivity Ratio between effort and cost
Static Capacity Store or configure permanently
Dynamic Capacity Process or manage data simultaneously with concurrent tasks
Analytics Latency Time delay experienced in core data processing
Round Trip Response Time elapsed between request and response
Scalability Ease, speed and affordability of changing performance qualities
Reliability MTBF, operation when faults occur, degree of recovery, no data loss
Table 14-1 Analytics Pipeline Properties [18]
14.3 ADVANCED ANALYTICS
Advanced analytics are intended to spot opportunities in real-time, make fast and accurate predictions and act with confidence at the point of decision. These advanced analytics fall into four major categories:
- descriptive analytics: gain insight from historical data with reporting, scorecards, clustering and such.
- predictive analytics: identify expected behaviors or outcomes based on predictive modeling using statistical and machine learning techniques.
- prescriptive analytics: recommend decisions using optimization, simulation etc.
The results of analytics can be used to support human decisions through visual analytics to enhance human understanding and generate confidence in a decision
Advanced Analytics use a combination of the following execution approaches:
- Automated: automated data analysis, modeling and result application to automatic and continuous executions (including improving the analytics and modeling themselves in systems capable of learning).
- Real-time: near instantaneous analytic results with correct timing information enabling appropriate and timely actions.
- Streaming: continuous results flow of on-the-fly analysis of live streaming data in memory without storage persistence until after analysis completion.
- Active: active sharing of real-time pattern discoveries with other components enabling fast and accurate responses to discovered system changes.
- Causal-oriented: identifying complex, causal relationships in the data anchored in well- understood physical laws enabling better analysis using new approaches such as physical modeling and combining physical modeling with neural network deep-learning capabilities.
- Distributed: shared processing and results generation leveraging dynamic inter- and intrafunctional domain relationships within and across II systems.
IIS place unique requirements on advanced analytics to include timing constraints, data volume constraints and safety criticality, as described below.
Timing constraints: If network latency cannot meet real-time requirements or the communication is not dependable, analytics must be performed in close proximity to the data sources and the systems that consume the results. For example, the results of image analytics of an autonomous vehicle must be made available to the model executor controlling the driving system within milliseconds.
Data volume constraints: Control systems that operate at high frequency and high speed, such an aircraft engine process large volume of time-series data of high resolution in both time and value. Network bandwidth constraints may make it infeasible to transport such large data volumes across the network. Dynamic Composition and Automated Interoperability, enables dynamic binding of the data to the analytic capabilities at the edge, and bursts of high volume data to the appropriate analytic systems on demand. When low-level, high-resolution data are analyzed locally, summary data can find useful patterns across fleets of systems.
Safety criticality constraint: Safety-critical situations such as the presence of a child in an autonomous vehicle requires instantaneous, zero-fault-tolerant analytic. Failure to execute a safety override because the image analytics failed due to poor image quality is not an option.
14.4 IIS RA ALIGNMENT
Advanced data processing plays a role in each of the four IIS Reference Architecture viewpoints. In the Business Viewpoint, stakeholders have a vision focused on achieving benefits from their investments that requires advanced, real-time data processing activities for continuing measurement of business performance and ultimately the return-on-investment (ROI). These business-driven system objectives can guide the identification of advanced data processing capabilities required in an IIS.
Advanced data processing activities in the Usage Viewpoint must be identified to support the required advanced data processing capabilities and to guide the design, implementation, deployment, operations and evolution of these capabilities.
From an implementation viewpoint perspective, the implementation of analytics must take into account the timing, data volume and safety constraints and the consideration of resilience. Because of these constraints, analytics may be distributed across an IIS architecture, for example, in each of the edge, platform, and enterprise tiers of a three-tier architecture pattern.
15 INTELLIGENT AND RESILIENT CONTROL
15.1 MOTIVATION
The control model prevailing in industrial automation systems today tends to be localized in scope and reactive in response, such as the limited control loop feedback mechanisms implemented by proportional-integral-derivative (PID) controllers. When we embark on the task of creating a control, even a simple PID controller, we must consider a number of system engineering factors in respect to the conditions, constraints on operation, and the context. We then build a mechanism that takes some inputs to produce some outputs including engineering data values (voltages, temperatures etc.) and control signals to hardware, (opening or closing a breaker). Most of these factors are kept in the heads of the control (systems?) engineers and are thus a black box.
In IISs, we intend to perform distributed rather than local control, and to make predictions about how the world will change as a result of control. Moreover, this control must be ‘intelligent and resilient’ so that it can operate within a dynamic and unpredictable environment, using a distributed, collaborative capability to sense, make sense of, and affect the world and so achieve the goals of the specific entity that is acting (the agent). However, to reason and make predictions about how other controllers will work, particularly in unpredictable circumstances and dynamic environments, etc., we need transparency into that black box—the head of the control engineer. We need to understand how those choices were made, and what models of the world, assumptions about the world, understanding of the actions an actuator can take, and so on, prompted those decisions.
By employing models, either explicit or implicit, we can affect the desired intelligent control of the resources available to the agent and enable planning to bring the world to a state more acceptable to our interests. By making these modeling choices explicit, we improve the communication with the users of the system, and enable more advanced approaches to resiliency.
15.2 CONSIDERATIONS
The control engineer makes these choices based on a number of considerations, including:
Is the model of the world fully or partially observable? In a chess game, where the world is completely observable, the rules are known, so a legal move has a deterministic result. We may not be able to precisely determine the opponents move, we know it will be from a list of legal moves, and once it has been made we will know which move in the list has been taken. On the other hand, in a world that is only partially observable, such as many card games where cards are hidden, we are forced to infer world state based on the actions of the opponent. This affects our choices of the decision theory to use, the way we will model the world, the kinds of recovery strategies that are available to us after a fault, etc.
Are actions deterministic or probabilistic? When dealing with actions that can fail, such as a game of billiards, we are forced to consider not only the position of the balls we want to create if our shot is successful (leading to the next shot we will take being easier), but also that if we are unsuccessful (leading to the next shot our opponent will take being harder). Many models presume sensing the world is ‘free’ in that it evolves continuously and outside of the influence of our decision making system, but taking a reading may require effort in that we have to move our sensor to observe something. That means that a world that might at one level of analysis appear to be fully observable is really only partially observable (because we don’t have the processing capability to digest all of the sensor information we may be receiving) and also that what we think is the ‘right’ choice may not be, because we didn’t see everything—the outcome of a particular action in a fully known state may be deterministic, but if we can’t fully know the state— if some portion of it is uncertain, then we may want to say that the outcome of the action is uncertain (probabilistic) as well.
Can we plan all at once, or must we plan-to-plan? One way to deal with uncertainty is to defer planning until we have more knowledge—that is we can ‘plan to plan’ in that we create a partial plan that includes ‘planning’ as an action that will be taken under certain circumstances.
Example: I may not know the train schedule to NY, so I have to plan to get the schedule before I buy the ticket. Since getting the schedule is insufficient to know which ticket to buy, I then have to plan to plan – decide now to postpone my decision as to which train to take, and thus the specifics of what I will do upon arrival. Or I may create a contingency plan, where I do all the work now iterating through every reasonable contingency, e.g., arrival before lunch, arrival after lunch, arrival after dinner, arrival after the subways are shut down, etc. It is a metacognitive action to decide which kind of plan I should create, but that decision can also be fixed at design time (i.e. the system will always generate a non-contingent plan, and if there are sufficient unknowns to prevent generation of such a plan, planning will fail with a list of unknowns to be satisfied).
Can we specify alternative methods to achieve goals? There’s usually more than one way to skin a cat, and just as there are several possible routes to travel from point A to point B, by specifying multiple non-redundant ways to achieve a goal we build in a mechanism for the system to have backup strategies. For instance, while raising the house temperature is best achieved by turning on the furnace, a fireplace can be used, or the stove, or electrical heaters – all alternative methods that can be used if the furnace temporarily is non-operational.
Can we specify methods to reclaim or recover resources (particularly after casualty)? Such methods may be as simple as instructions for rebooting the network routers in case the network stops working, to strategies for reducing electrical usage to allow high current machinery to be started. Similar to the alternative methods, such an approach allows us to construct resilient systems – those that can reconstitute their capabilities after a failure. One can easily imagine resources having been assigned to processes (such as a database) to be in an unknown state during use, but should the process fail, we need to have a method to return those resources to some kind of known good state so they can be used again without having to wait for repair. In a database, this might be a rollback; in a nuclear power plant, this might be an orderly shutdown followed by a cold restart.
Do we want to learn and adapt to our inputs over time? Our main concern is application to dynamic situations – so the connection between the inputs and outputs may not be known perfectly at design time, and may change over time. For instance, if we are controlling both heat and humidity in a house, we may not know what kind of insulation the house has, and the system may not even know the time of the year it is (so if heating or cooling will be called for, if humidity will need to be added or subtracted, and at what rate). We will know that cooling will dehumidify. But presuming we have (unlike most residential systems) the ability to change the rate of cooling or adjust the balance between cooling and dehumidification, we may want to do so based on how the system has reacted in the past to such controls and furthermore be willing to readapt since seasonal changes will alter the response.
These considerations allow building appropriate models of and the relationships between the following that were previously mapped in the control engineer’s head:
- the (relevant) world (context, environment, state of the universe, etc.),39
- action (both atomic and compound—e.g. a typical process that does something useful),
- communication (as a kind of action),
- intention (as of other agents),
- sensors,
- actuation and
- ethics (that is, those actions we must and must not do within a context)
15.3 FUNCTIONAL COMPONENTS
Figure 15-1 is a sketch of one way we might architect an intelligent control for a very dynamic environment. As a top-level decomposition, we have the following modules:
Deliberative and reactive planners: Long-horizon plans (typically called “deliberative”) set goals. Short-horizon planners (“reactive”) make satisficing real-time decisions (addressing resiliency) using a long-term plan to guide executing the plan in the current situation. Thus even when the long-term plan is obsolete, i.e. we cannot execute the plan as written, the reactive planner must be able to modify it on the fly to fit the actual circumstances. The planners handle most physical or logical planning constraints. For example, you cannot put down something you are not holding and you cannot use two positives to make a negative.40
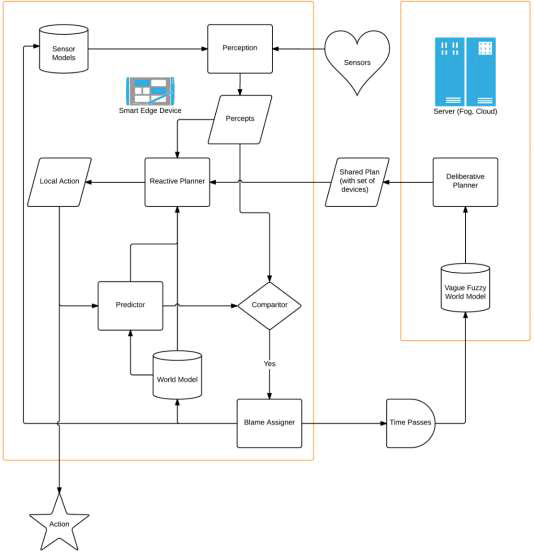
Figure 15-1 Intelligent Control Model
The deliberative planner needs more resources to establish a long-term plan, and is driven on a general understanding of the current world state, but is not the ‘man on the scene.’ That is the reactive planner, in the tight loop with the sensors and actuators making moment-to-moment decisions—guided by the long term plan, but able to override actions—the long term plan provides the moral equivalent of ‘commander’s guidance’ while the reactive planner is the noncommissioned officer making tactical decisions under fire.
Because planning is a joint activity, and ‘the plan’ may not be visible to any particular agent or set of agents—since much of the plan is parochial and by the time it is observed by a (remote) agent, it will have been implemented or overtaken by events. A flexible mechanism for planning and implementing plans is therefore called for. One recommendation is a small but flexible reactive planner in the device itself and a deliberative (offline) planner provided as a service by a larger system or through remote service providers.
Predictor and precepts: Because plans may fail in an uncertain and dynamic world, we should expect that any particular agent’s plan may fail, and that its models may make mistakes and fail. We therefore need perception to look at the relevant part of the world (driven by the plan) and for it to generate percepts—individual perceptions of interest to the agent.
The Predictor function informs the reactive planner what the likely outcome of planned actions will be, and through the comparator can look at what actually happened as the result of taking an action. If there is no difference, the operation continues but when there is a difference, we invoke the Blame Assigner (see below). A predictor function predicts what the state of the world will be at some point in the future, given an action or lack of action by that agent. (We regard not taking an action as an action: waiting). We can break the predictor down into two components: one that uses the models to chain out a possible future, and another that learns from experience. A learning function also requires additional parameters, including at least the inertia (how long to wait until making a prediction) or entropy rate (how likely is the pattern of the next input to be different from the past). (As an example, if we see the time series 0, 1, 1, 2, 3, 5, 8, 13: at what point do we react and say ‘Fibonacci’—after the 2? The 3? The 13? At what point do we go back and make sure we are still seeing Fibonacci numbers? Every time? Every xx numbers? What if the pattern repeats? Stops and changes to some other pattern?).
Blame assigner: Given a world model, a predictor and a plan, we can predict the likelihood our plan will succeed, and then amend the plan to increase the likelihood of success (in probabilistic models). But we may be ‘surprised’ when our action does not have the intended effect. The ‘blame assigner’ makes the decision as to why things aren’t as we thought they would be by considering a number of possible scenarios to determine the component at fault when something goes awry. It could be bad sensing where the control did generate the expected effect, but our decision to act was based on incorrect sensor data, or the world was not in the state we thought it was when we selected the action. It could be because of a bad model in which we have the wrong effects or likelihood of effects from our action, or because of the conditions under which the action is effective were incomplete, etc. It could also be because of faulty action in which e.g. we intended to press button A, but actually pressed button B, etc.
Ethical governor: An ethical governor (not in this diagram) might also be used to vet the action decisions to make sure that the agent does not perform any action it ‘must not’ perform (for, e.g., safety, security, or other reasons) and does perform any action it ‘must’ perform. It is a special deontic checker that validates that a course of action is within the scope of agreed upon ethics within appropriately negotiated, communicated, and represented community policies. The ethical governor must have the ability to override the agents’ intentions. We give ethical rules special treatment because they do not tend to be an issue at the level of action selection but rather the overall plan pragmatics.41
Security, safety and other models implemented by the ethical governor would be able to reject a request made by an operator or other agents. The autonomy implemented by an agent would always have ‘final say’ on accepting or rejecting a request.
Another task of the ethical governor is to determine when it is safe to dynamically change a device’s behavior and/or performance through updating the device by deciding if the update is appropriate for the current circumstance and does not violate a safety or security constraint.
The agent should also store its own meta-information, so as to advertise its capabilities to the community, or to describe them in whole or in part in answer to a query about them.42
16 DYNAMIC COMPOSITION AND AUTOMATED INTEROPERABILITY
16.1 MOTIVATION
IISs require secure, safe and scalable composition of many diverse components from a variety of sources, often with different protocols, to deliver reliable end-to-end services. Given that distributed Industrial Internet applications are intended to be responsive to dynamic environments and that related technologies and standards are rapidly evolving, resilient IISs need to adapt flexibly to optimize services as environments change and to avoid disruptions as components are updated, upgraded and replaced. IISs present new use-cases in distributed computing that will drive advances in information technology architecture.
Service Orientation defines a logical framework for thinking about exchanging capabilities and data via distributed services and the ability to compose services into high-order applications and business processes. Though implementations vary and evolve, in general practice, service compositions are models of statically connected components. The relationships between components are defined in advance. At run-time, “orchestration engines” merely execute the composition. The method of composition design do not provide for any adaptation in response to change in the environment or of the components themselves. This tight coupling makes the compositions brittle; change requires manual redesign and generation of a new model or else the service is likely to break. The approach is not scalable in dynamic IIS environments. Advance testing of such service compositions can only validate the model in a controlled environment that is not representative of real-world operations.
IISs require a flexible method of composing services, so components can be dynamically integrated at run-time to enable adaptable services. Instead of static point-to-point connections, the demands of IISs need semantic interoperability to support many-to-many connections. In this approach, compositions indirectly link components using metadata references to a domain information model. Compositions represent a set of references to the information model, rather than a fixed set of named components. By separating the model from the implementation, semantic service compositions support metadata-driven policy-controlled orchestration that interprets references at run-time to dynamically discover components and their connections, as well as their transport and transformation details and integrate them on-demand. This loosely coupled approach automates interoperability and enables policy-based optimization for flexible and dynamic IISs that can adapt to change and re-configure network resources accordingly. Since semantically composed services have abstract contracts that are dynamically translated to concrete implementations, simulations can demonstrate the impact of real-time change and provide an execution trace that can be validated.
Many of these concepts were part of the original vision of Service Oriented Architecture (SOA).43
In the early days of SOA, the software industry focused on static solutions that it could bring to market quickly to satisfy pressing business demand for distributed computing. While dynamic features were perhaps ahead of their time, IISs now clearly require ‘smart’, adaptable composite applications. The demands of IIS drive change in several areas:
Situational awareness: Static solutions do not provide mechanisms for resolving possible incompatible assumptions about, for example, the operating environment, the deployment context, the interacting entities, and so on.
Workload diversity: Static compositions cannot change their stripes. In the real world, an end-toend process may be a collaboration, choreography or orchestration with elements of various levels of autonomy. Many responses may be taking place simultaneously and would require flexible compositions in response to event.
Complex relationships: In IISs any element may have peer, parent and child relationships and thus varying roles and perspectives. This applies recursively to the participating elements, which may represent complex systems and involve a network of sub-systems. In a static solution, as tightly coupled complexity goes up, resilience goes down.
Dynamic relationships: In IISs relationships are constantly forming and un-forming, as in a ‘friend-of-a-friend network’. The dynamics are changing constantly, creating on-the-fly activity and changing state among collaborating components. A self-forming composition may come into being when there is value in coordination, and then disengage or be uninvited from the group as events unfold.
In short, static, compartmentalized and centralized methods are not suited for dynamic optimization that concurrently satisfies multiple constraints for dynamic, diverse and distributed interactions expected in an IIS, and this prompts a shift from static models of integration and orchestration to “Dynamic Composition and Automated Interoperability.”
16.2 CONSIDERATIONS
Practices and standards established today may enable or constrain future capabilities, so any approach must provide enduring value, and delay the need for expensive and time-consuming re-evaluation and re-design of the architecture.
By separating models from implementation, dynamic composition and automated interoperability supports a future-proofed IIS architecture that accommodates change by design (i.e. integration decisions are postponed to run-time to allow for optimization and adaptation).
We compose loosely coupled components using metadata references, contained in an information model that captures logical models of services based on abstract contracts. The abstract contracts de-couple system capability and control from the details of the implementation and infrastructure complexity. Consequently, the system capabilities can be declaratively described in the form of policy to bring about the desired service, function, conditions, and so on, without having to understand low-level implementation details.
Since the abstract contracts do not explicitly define the implementation, they need to be interpreted at run-time by an agent that acts as an intermediary responding to events. Every event is an opportunity for an agent to add value, not just to perform a static script, but to discover patterns, perform functions, run analytics and otherwise ‘reason’.
Agents resolve all references to find-and-bind the right resources just-in-time by performing all necessary connections and transformations, and to provide an optimal, context-enhanced response. Moreover, these agents monitor the responses of the employed services to ascertain if they are, in fact, responsive in accordance to the contract and otherwise replace the underperforming services to achieve the desired end-goal.
To maintain Quality of Service (QoS) and Quality of Experience (QoE), applications in an IIS may require visibility to the state of the interacting elements and network resources so it can observe and react to changes in connectivity and faults. This requires information be aggregated and translated into a common abstraction so system management applications can respond to events with any necessary re-configuration of the infrastructure and service implementation. The same high-level abstraction supports change at the application level, with the same QoS and QoE implications, to provide for sustainability of the end-to-end business capability.
In short, dynamic composition and automated interoperability must allow for real-time, datadriven, policy-controlled integration of services, and systematically late-bound at run-time, rather than integrating them in advance at design-time.
This approach for IISs, as a natural advancement in the evolution of system composition and service orchestration, has other significant benefits:44
Virtually centralized policy control: Security, business compliance and IT governance policies can be linked to abstract contracts addressing the historic challenge of managing consistent policy enforcement of system-wide concerns across diverse and distributed components.
Service adaptability: Since abstract contracts are not tightly coupled to any resources in advance, they can automatically evolve with updates and upgrades of underlying components without interrupting the operations.
DevOps Productivity: Automating interoperability eliminates repetitive, error-prone and time- consuming integration work, accelerating service delivery and reducing cost.
16.3 FUNCTIONAL COMPONENTS
The key functional components required to support the dynamic composition and automated integration are:
Integration contract management:45 The integration contract management functional component provides capabilities for managing abstract contracts for automated interoperability, including:
- creation, query, update and deletion of abstract contracts for automated integration
- management of policies that apply to dynamic compositions.
Dynamic composition: The dynamic composition functional component provides run-time capabilities for composing system elements, in adherence to abstract contracts for automated integration, including:
- monitoring the status of the distributed system
- automated addition and removal of system components to a composition, in reaction to changes of system state
- creation and deletion of links between the interfaces of composed components
Notes
23 A path or means (e.g. viruses, e-mail attachment, Web pages, etc.) by which an attacker can gain access to a computer or network server in order to deliver malicious payloads or outcome.
24 Such as the ARM TrustZone and Intel Software Guard Extensions.
25 Fault tolerance traditionally addresses system internal faults caused by a bug, hardware failure, or some kinds of internal error states. Resilience has a bigger scope in that it focuses on harmful elements external to the system, often introduced by an adversary, that tend to be unpredictable and unforeseen by the system’s designers.
26 Sometimes called self-optimizing (as part of self-CHOP), but optimization is often too strong a concept— we will accept suboptimal but improved capabilities as part of recovery.
27 Of particular importance, “what are the N most likely things the adversary may do?” “What are the M most dangerous things they may do?” Planning generally has to address all of these contingencies, the longer one has for planning, the larger N and M can be—which means that the unit can be ready for a wider variety of unfolding circumstances.
28 The exact amount depends on the service—marines have a lot more doctrinal flexibility than army units do for instance.
29 “Observe, Orient, Decide, Act” Col. Boyd’s brilliant insight into how fighter pilots operate. If one can execute one’s OODA loop faster than the adversary can, they will usually win the battle because they can react to unfolding circumstances and in fact create unsettling circumstances faster than the adversary can. (This has also been applied to business management).
30 http://en.wikipedia.org/wiki/Reactive_planning
31 Other doctrine, such as security, privacy, etc. may come into play as well, but safety is the most important as it is the hardest to recover from.
32 This model is based on Page et al: Toward a Family of Maturity Models for the Simulation Interconnection Problem [29]
33 The considerations here are similar to those studied under linguistics and the philosophy of language— to ask how it is possible for humans to communicate, for us to know someone else’s meaning, and how we can learn new things without actually experiencing them through language, by, for example reading a book.
34 Agent-based systems generally spill quite a bit of ink defining ‘performative’ speech acts (those that are performed by way of saying them, that is, when I say, “I promise you…,” I have done something, namely made a promise!). See, e.g., [31]
35 The three levels of understanding in communication discussed here loosely map to the corresponding levels of interoperability as defined in the Conceptual Interoperability [13], i.e. technical, syntactic, semantic and pragmatic understanding to technical, syntactic, semantic and pragmatic interoperability, respectively. We use the term understanding in place of interoperability here to avoid the confusion that might be otherwise caused by also using the term interoperability in the levels of communication (integrability, interoperability and composability). However, phrases such as semantic interoperability will be used in other sections of this document.
36 Data quality monitoring and sensor health monitoring are common applications for data reduction and analysis
37 Essentially, the difference is in the active element – in the first case, a knowledge base contains the data and a query is run against that data such as SQL. In the latter case, the query is fixed in a stream processor and the data is run through it to filter out anything from the stream that does not fit. The latter can be a better fit when the data being generated is too voluminous to store, however, once filtered the ‘filtered out’ data is lost.
38 Extract, transform, load, a process in database usage and especially in data warehousing.
39 Modeling invariably involves abstracting away irrelevant detail. Deciding what is and what is not relevant is part of the job and risks of systems engineering.
40 Yeah, yeah. [32]
41 Ron Arkin: Governing Lethal Behavior: Embedding Ethics in a Hybrid Deliberative/Reactive Robot Architecture [22] http://www.cc.gatech.edu/ai/robot-lab/online-publications/formalizationv35.pdf
42 Note that this does not require the agent to understand the meta-information, just be able to report it. The meta-information could then be parsed or interpreted by the receiver, through either pattern matching or general reasoning.
43 Using OMG’s Model Driven Architecture (MDA) to Integrate Web Services http://www.omg.org/mda/mda_files/MDA-WS-integrate-WP.pdf (2002) [20] and New OASIS Committee Organizes to Provide Semantic Foundation for SOA (2005) [21]
44 For more details, please see “Semantic SOA makes Sense!” [19].http://enterpriseweb.com/semantic-soa-makes-sense-2/
45 Traditional SOA composition patterns, such as orchestration, collaboration and choreography can be supported through static integration contracts, using existing languages such as WS-BPEL. Languages for specifying more dynamic automated integration patterns may require new standardization.